Un confronto bayesiano dei risultati degli studenti al termine della scuola con R e brms
Bayesian comparison of students' results at the end of school using R and brms
ANOVA – Stile Bayesiano
Molto si dice su cosa vogliamo fare quando lasciamo la scuola. Ci viene chiesto fin da piccoli cosa vogliamo fare da grandi, per poi trascorrere 13 anni nell’istruzione pre-terziaria. Nella politica pubblica, si dà molto rilievo alle differenze tra i sistemi scolastici governativi, cattolici e indipendenti, soprattutto quando si tratta del finanziamento pubblico delle scuole non governative e di come devono essere allocate le risorse.
C’è qualche differenza reale tra i risultati degli studenti in base al settore scolastico?
In Victoria, in Australia, il governo statale conduce un’indagine annuale per valutare i risultati post-scuola superiore (On Track Survey). Questo dataset (disponibile in base alla licenza CC BY 4.0) è disponibile in diversi anni e analizzeremo solo il più recente disponibile al momento della stesura di questo articolo, ovvero il 2021.
Questo articolo cercherà di rispondere a queste domande applicando metodologie di analisi bayesiana, utilizzando il pacchetto R brms.
- Optimizzazione del viaggio in Europa algoritmi genetici e Google Maps API risolvono il problema del commesso viaggiatore
- Come eccellere nel bootcamp di Data Science Una guida completa
- Elaborazione del linguaggio naturale per principianti assoluti
Carica librerie e dataset
Di seguito carichiamo i pacchetti necessari, il dataset è presentato in un formato di report ampio, con molte celle unite. R non gradisce questo, quindi dobbiamo fare un po’ di codifica manuale per rinominare i vettori e creare un data frame ordinato.
library(tidyverse) #Pacchetto meta del Tidyverselibrary(brms) #Pacchetto di modellazione bayesianalibrary(tidybayes) #Funzioni di supporto e geometrie di visualizzazione ordinate per modelli bayesianilibrary(readxl)df <- read_excel("DestinationData2022.xlsx", sheet = "SCHOOL PUBLICATION TABLE 2022", skip = 3)colnames(df) <- c('vcaa_code', 'school_name', 'sector', 'locality', 'total_completed_year12', 'on_track_consenters', 'respondants', 'bachelors', 'deferred', 'tafe', 'apprentice_trainee', 'employed', 'looking_for_work', 'other') df <- drop_na(df)Ecco un esempio di come appare il nostro dataset.
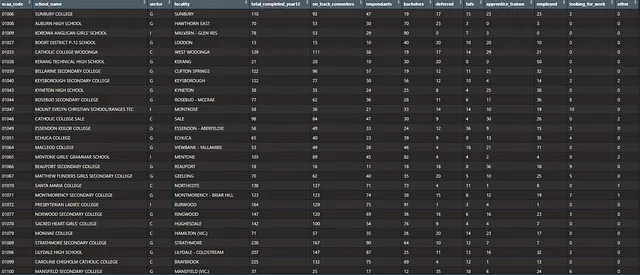
Il dataset ha 14 campi.
- Codice VCAA – ID amministrativo per ogni codice
- Nome della scuola
- Settore – G = Governo, C = Cattolico e I = Indipendente
- Località o sobborgo
- Numero totale di studenti che completano l’anno 12
- Consenso On Track
- Rispondenti
- Il resto delle colonne rappresenta la percentuale di rispondenti per ciascun risultato
Per gli scopi del nostro studio trasversale, siamo interessati alle proporzioni dei risultati per settore e quindi dobbiamo convertire questo data frame ampio in un formato lungo.
df_long <- df |> mutate(across(5:14, ~ as.numeric(.x)), #converti tutti i campi numerici acquisiti come caratteri across(8:14, ~ .x/100 * respondants), #calcola i conteggi dalle proporzioni across(8:14, ~ round(.x, 0)), #arrotonda a numeri interi respondants = bachelors + deferred + tafe + apprentice_trainee + employed + looking_for_work + other) |> #rivaluta i rispondenti totali |> filter(sector != 'A') |> #Basso volume select(sector, school_name, 7:14) |> pivot_longer(c(-1, -2, -3), names_to = 'outcome', values_to = 'proportion') |> mutate(proportion = proportion/respondants)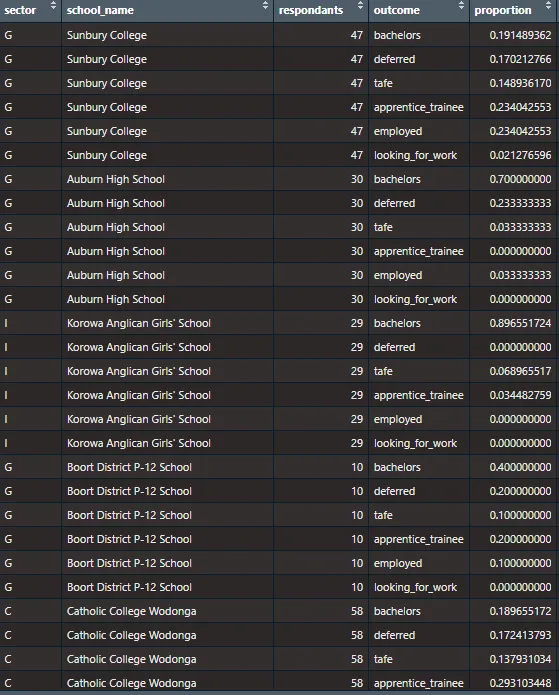
Esplorazione dei dati
Visualizziamo e riassumiamo brevemente il nostro dataset. Il settore governativo ha 157 scuole, l’Indipendente ne ha 57 e il cattolico ne ha 50.
df |> mutate(sector = fct_infreq(sector)) |> ggplot(aes(sector)) + geom_bar(aes(fill = sector)) + geom_label(aes(label = after_stat(count)), stat = 'count', vjust = 1.5) + labs(x = 'Settore', y = 'Conteggio', title = 'Conteggio delle scuole per settore', fill = 'Settore') + scale_fill_viridis_d(begin = 0.2, end = 0.8) + theme_ggdist()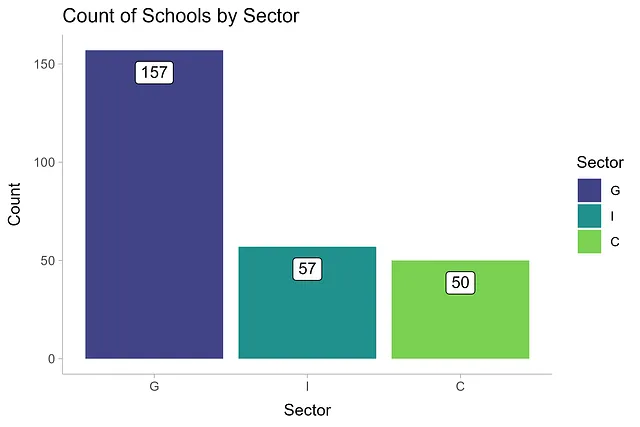
df_long |> ggplot(aes(sector, proportion, fill = outcome)) + geom_boxplot(alpha = 0.8) + geom_point(position = position_dodge(width=0.75), alpha = 0.1, color = 'grey', aes(group = outcome)) + labs(x = 'Settore', y = 'Proporzione', fill = 'Risultato', title = 'Boxplot delle proporzioni dei rispondenti per settore e risultato') + scale_fill_viridis_d(begin = 0.2, end = 0.8) + theme_ggdist()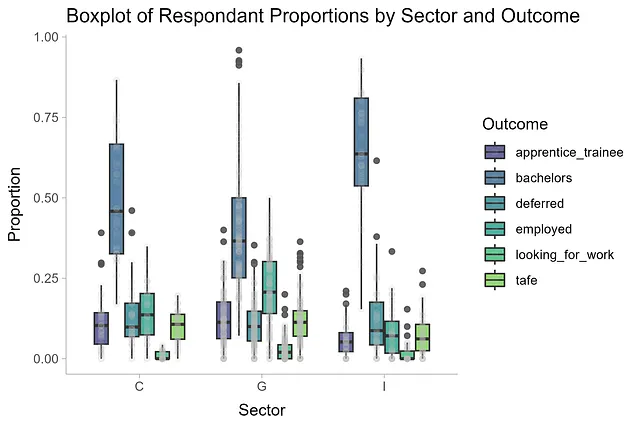
Le distribuzioni raccontano una storia interessante. Il risultato delle lauree mostra la maggior variabilità tra tutti i settori, con le scuole Indipendenti che hanno la mediana più alta di studenti che scelgono di proseguire gli studi universitari. È interessante notare che le scuole governative hanno la mediana più alta di studenti che trovano impiego dopo il diploma di scuola superiore. Gli altri risultati non variano molto – torneremo su questo presto.
Modellistica statistica – Regressione con verosimiglianza beta
Siamo interessati alle proporzioni degli studenti per scuola e ai loro risultati dopo il diploma di scuola superiore. Una verosimiglianza beta è la nostra migliore scelta in questi casi. brms è un pacchetto brillante sviluppato da Buerkner per sviluppare modelli bayesiani. Il nostro obiettivo è modellare la distribuzione delle proporzioni per risultato e settore.
La regressione beta modella due parametri, μ e φ. μ rappresenta la proporzione media, e φ è una misura di precisione (o varianza).
Il nostro primo modello è rappresentato di seguito, notare che stiamo già iniziando con un’interazione tra Settore e Risultato perché questa è la domanda a cui vogliamo che il modello risponda, ed è quindi un modello ANOVA.
Chiediamo al modello di creare termini Beta individuali per ogni combinazione di Settore e Risultato, con un termine φ comune, cioè modellare diverse medie di proporzione con la stessa varianza. Ci aspettiamo che il 50% di queste proporzioni si trovi tra (-3, 1) sulla scala logit o (0.01, 0.73) come proporzioni. Questo è sufficientemente ampio ma informato. La stima Phi globale è un numero positivo, quindi utilizziamo una distribuzione gamma sufficientemente ampia.
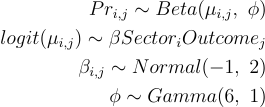
# Modellizzazione della proporzione con l'interazione tra Settore e Risultato utilizzando Beta - Termine Phi comune
m3a <- brm( proportion ~ sector:outcome + 0, family = Beta, data = df_long |> mutate(proportion = proportion + 0.01), # La regressione Beta non può gestire risultati pari a 0, quindi qui aggiungiamo una piccola incremento prior = c(prior(normal(-1, 2), class = 'b'), prior(gamma(6, 1), class = 'phi')), iter = 8000, warmup = 1000, cores = 4, chains = 4, seed = 246, save_pars = save_pars(all = T), control = list(adapt_delta = 0.99, max_treedepth = 15)) |> add_criterion(c('waic', 'loo'), moment_match = T)summary(m3a)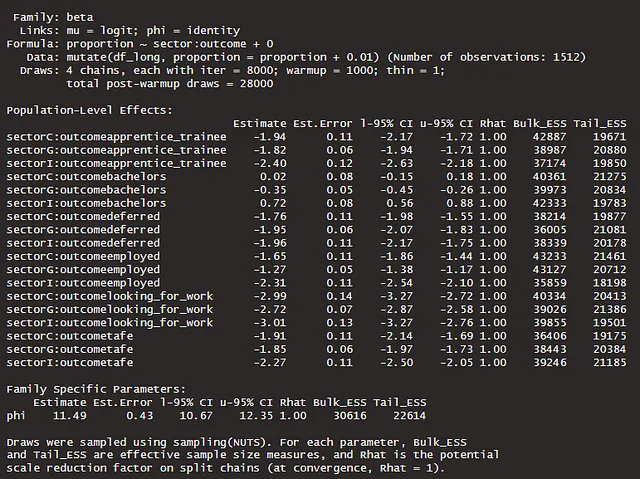
Si noti che nella configurazione del modello abbiamo aggiunto un incremento del 1% a tutte le proporzioni – ciò perché la regressione Beta non gestisce i valori zero. Abbiamo cercato di modellare questo con la beta inflazionata da zero ma ci ha impiegato molto più tempo per convergere.
Allo stesso modo, possiamo modellare senza un phi comune, questo intuitivamente ha senso dato ciò che abbiamo osservato nelle distribuzioni sopra, c’è variazione tra ciascuna delle combinazioni di settore e risultato. Il modello è definito di seguito.
m3b <- brm( bf(proportion ~ sector:outcome + 0, phi ~ sector:outcome + 0), family = Beta, data = df_long |> mutate(proportion = proportion + 0.01), prior = c(prior(normal(-1, 2), class = 'b')), iter = 8000, warmup = 1000, cores = 4, chains = 4, seed = 246, save_pars = save_pars(all = T), control = list(adapt_delta = 0.99)) |> add_criterion(c('waic', 'loo'), moment_match = T)summary(m3b)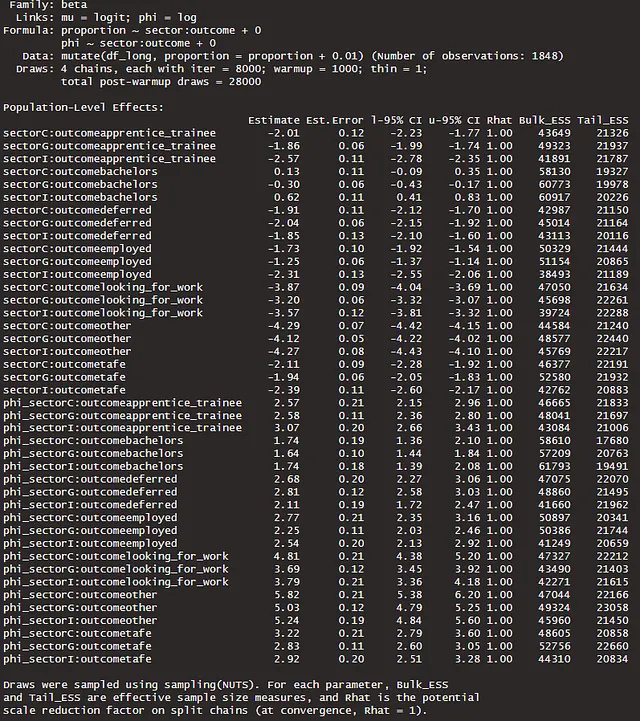
Diagnostica e Confronto del Modello
Con due modelli a disposizione, ora confrontiamo la loro accuratezza predittiva fuori campione utilizzando la stima LOO bayesiana della densità di probabilità puntiforme prevista (elpd_loo).
comp <- loo_compare(m3a, m3b)print(comp, simplify = F)
In parole semplici, più alto è il valore atteso del log punto per punto lasciato fuori, maggiore è l’accuratezza predittiva su dati non visti. Questo ci fornisce una buona misura relativa dell’accuratezza del modello tra i modelli. Possiamo verificare ulteriormente ciò completando un controllo predittivo posteriore, un confronto tra valori osservati e simulati. Nel nostro caso, il modello m3b è il miglior modello per i dati osservati.
alt_df <- df_long |> select(sector, outcome, proportion) |> rename(value = proportion) |> mutate(y = 'y', draw = 99) |> select(sector, outcome, draw, value, y)sim_df <- expand_grid(sector = c('C', 'I', 'G'), outcome = unique(df_long$outcome)) |> add_predicted_draws(m3b, ndraws = 1200) |> rename(value = .prediction) |> ungroup() |> mutate(y = 'y_rep', draw = rep(seq(from = 1, to = 50, length.out = 50), times = 504)) |> select(sector, outcome, draw, value, y) |> bind_rows(alt_df)sim_df |> ggplot(aes(value, group = draw)) + geom_density(aes(color = y)) + facet_grid(outcome ~ sector, scales = 'free_y') + scale_color_manual(name = '', values = c('y' = "darkblue", 'y_rep' = "grey")) + theme_ggdist() + labs(y = 'Densità', x = 'y', title = 'Distribuzione delle Proporzioni Osservate e Riprodotte per Settore e Risultato')
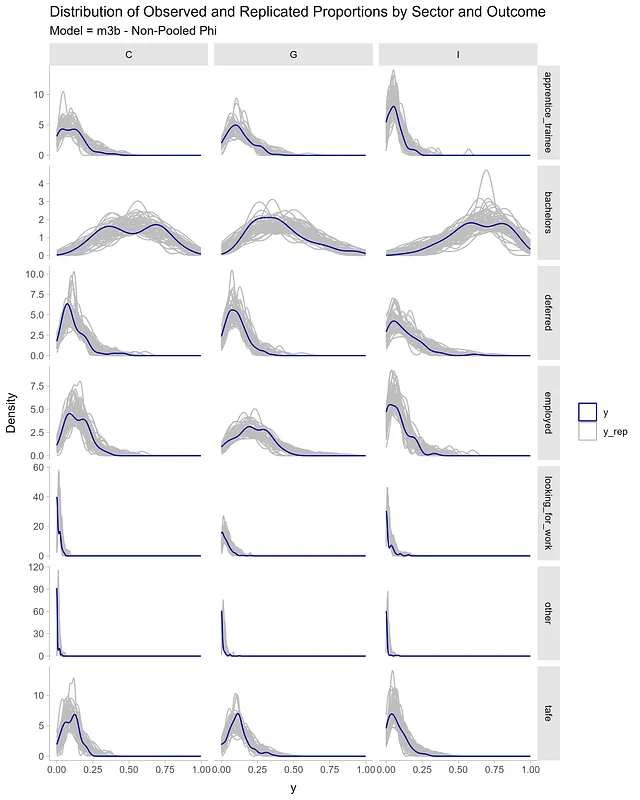
Il modello m3b, dato il suo termine di varianza non raggruppato o termine phi, è in grado di catturare meglio la variazione nelle distribuzioni di proporzione per settore e risultato.
ANOVA – Stile Bayesiano
Ricordiamo che la nostra domanda di ricerca riguarda la comprensione se ci sono differenze nei risultati tra i settori e quanto sono significative. Nelle statistiche frequentiste, potremmo utilizzare ANOVA, un’approccio di differenza delle medie tra gruppi. Il punto debole di questo approccio è che i risultati forniscono una stima e un intervallo di confidenza, senza un senso di incertezza su queste stime, e un valore p controintuitivo che indica se la differenza tra le medie è statisticamente significativa o meno. No, grazie.
Sotto generiamo un insieme di valori attesi per ogni interazione tra settore e combinazione di risultati, poi utilizziamo la funzione eccellente tidybayes::compare_levels() che fa tutto il lavoro pesante. Calcola la differenza tra le medie posteriori tra i settori per ogni risultato. Abbiamo escluso il risultato ‘altro’ per brevità.
new_df <- expand_grid(sector = c('I', 'G', 'C'), outcome = c('apprendista_allievo', 'laurea', 'posticipato', 'occupato', 'in_cerca_di_lavoro', 'tafe'))epred_draws(m3b, newdata = new_df) |> compare_levels(.epred, by = sector, comparison = rlang::exprs(C - G, I - G, C - I)) |> mutate(sector = fct_inorder(sector), sector = fct_shift(sector, -1), sector = fct_rev(sector)) |> ggplot(aes(x = .epred, y = sector, fill = sector)) + stat_halfeye() + geom_vline(xintercept = 0, lty = 2) + facet_wrap(~ outcome, scales = 'free_x') + theme_ggdist() + theme(legend.position = 'bottom') + scale_fill_viridis_d(begin = 0.4, end = 0.8) + labs(x = 'Differenza Proporzionale', y = 'Settore', title = 'Differenze nelle Medie Posteriori per Settore e Risultato', fill = 'Settore')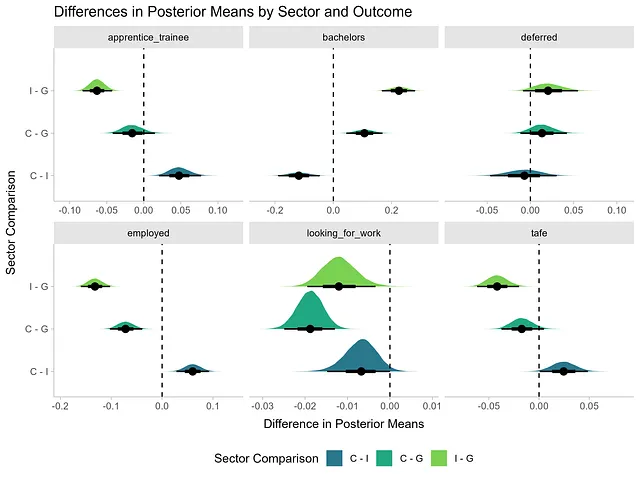
Alternativamente, possiamo riassumere tutte queste distribuzioni con una tabella ordinata per una più facile interpretazione e un intervallo di credibilità dell’89%.
marg_gt <- epred_draws(m3b, newdata = new_df) |> compare_levels(.epred, by = sector, comparison = rlang::exprs(C - G, I - G, C - I)) |> median_qi(.width = .89) |> mutate(across(where(is.numeric), ~round(.x, 3))) |> select(-c(.point, .interval, .width)) |> arrange(outcome, sector) |> rename(diff_in_means = .epred, Q5.5 = .lower, Q94.5 = .upper) |> group_by(outcome) |> gt() |> tab_header(title = 'Distribuzioni Marginali per Settore per Risultato') |> #tab_stubhead(label = 'Confronto Settore') |> fmt_percent() |> gtExtras::gt_theme_pff()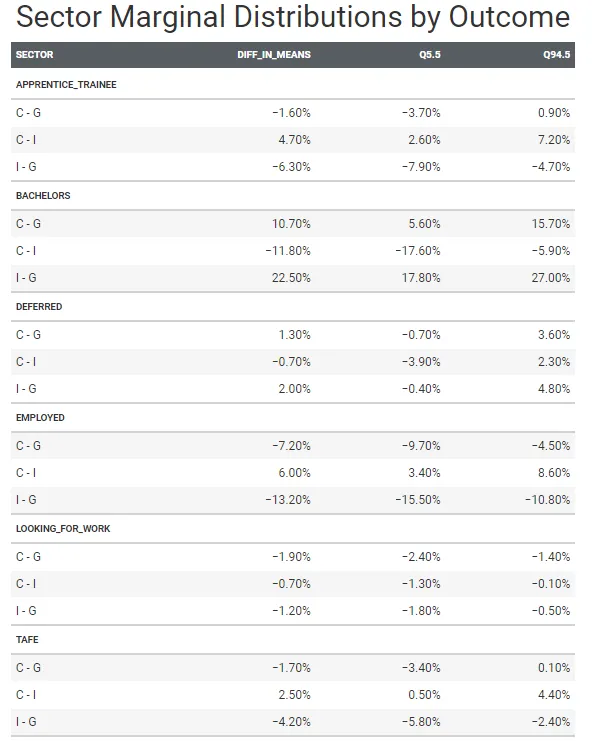
Ad esempio, se dovessimo riassumere un confronto in un rapporto formale, potremmo scrivere quanto segue.
Gli studenti delle scuole statali sono meno propensi a iniziare una laurea triennale rispetto ai loro omologhi delle scuole cattoliche e indipendenti dopo il completamento del VCE.
In media, il 42,5% (tra il 39,5% e il 45,6%) degli studenti delle scuole statali, il 53,2% (tra il 47,7% e il 58,4%) degli studenti delle scuole cattoliche e il 65% (tra il 60,1% e il 69,7%) degli studenti delle scuole indipendenti iniziano l’istruzione universitaria dopo il completamento del 12° anno di studi.
C’è una probabilità posteriore dell’89% che la differenza tra l’iscrizione universitaria degli studenti cattolici e quelli delle scuole statali sia compresa tra il 5,6% e il 15,7%, con una media del 10,7%. Inoltre, la differenza tra l’iscrizione universitaria degli studenti delle scuole indipendenti e quelli delle scuole statali è compresa tra il 17,8% e il 27%, con una media del 22,5%.
Queste differenze sono sostanziali e c’è una probabilità del 100% che queste differenze non siano nulle.
Sommario e conclusione
In questo articolo abbiamo dimostrato come modellare dati proporzionali utilizzando una funzione di verosimiglianza Beta mediante il modellamento bayesiano, per poi eseguire un’ANOVA bayesiana per esplorare le differenze nei risultati proporzionali tra i settori.
Non abbiamo cercato di creare una comprensione causale di queste differenze. Si può immaginare che ci siano diversi fattori che influenzano le prestazioni degli studenti individuali, come il contesto socioeconomico, il livello di istruzione dei genitori, oltre agli impatti a livello scolastico, come le risorse disponibili, ecc. È un’area di politica pubblica estremamente complessa che spesso si blocca nella retorica del gioco a somma zero.
Personalmente, sono la prima persona della mia famiglia allargata ad aver frequentato e completato gli studi universitari. Ho frequentato una scuola superiore pubblica di livello medio e ho ottenuto voti abbastanza alti per essere ammesso alla mia prima scelta. I miei genitori mi hanno incoraggiato a perseguire gli studi, entrambi scegliendo di lasciare la scuola all’età di 16 anni. Mentre questo articolo fornisce prove che la differenza tra le scuole statali e non statali è reale, è puramente descrittivo.




