Modelli di base per il ragionamento sui grafici.
Basic models for reasoning on graphs.
Pubblicato da Julian Eisenschlos, Research Software Engineer, Google Research
Il linguaggio visuale è la forma di comunicazione che si basa su simboli pittorici al di fuori del testo per trasmettere informazioni. È ubiquitario nella nostra vita digitale sotto forma di iconografia, infografiche, tabelle, grafici e diagrammi, estendendosi al mondo reale in segnali stradali, fumetti, etichette alimentari, ecc. Per questo motivo, far sì che i computer comprendano meglio questo tipo di media può aiutare nella comunicazione e nella scoperta scientifica, nell’accessibilità e nella trasparenza dei dati.
Mentre i modelli di computer vision hanno compiuto enormi progressi utilizzando soluzioni basate sull’apprendimento dall’avvento di ImageNet, l’attenzione si è concentrata sulle immagini naturali, dove tutti i tipi di compiti, come la classificazione, la risposta alle domande visive (VQA), la didascalia, la rilevazione e la segmentazione, sono stati definiti, studiati e in alcuni casi avanzati per raggiungere le prestazioni umane. Tuttavia, il linguaggio visuale non ha ottenuto un livello simile di attenzione, probabilmente a causa della mancanza di grandi set di addestramento in questo spazio. Ma negli ultimi anni sono stati creati nuovi dataset accademici con l’obiettivo di valutare i sistemi di risposta alle domande su immagini di linguaggio visuale, come PlotQA, InfographicsVQA e ChartQA.
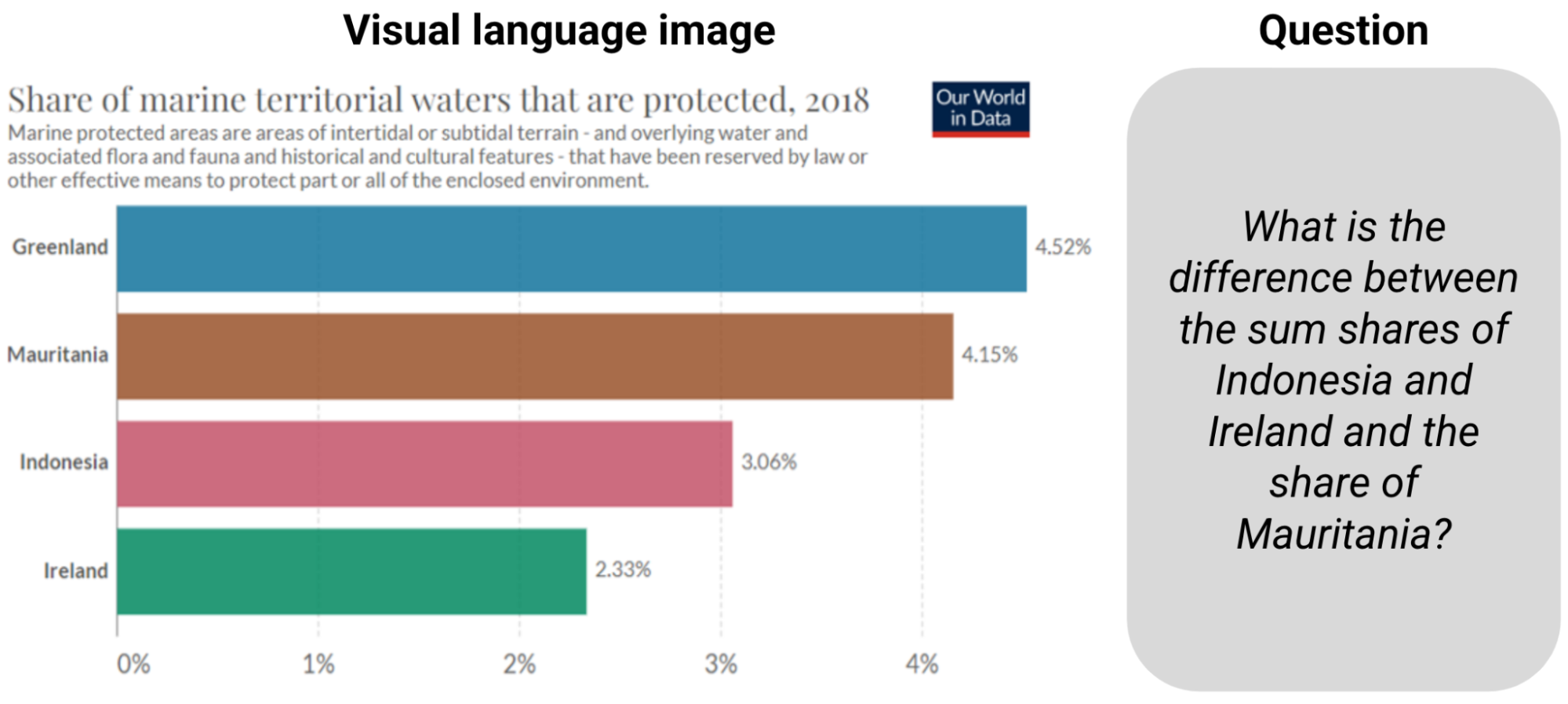 |
| Esempio da ChartQA. Per rispondere alla domanda è necessario leggere le informazioni e calcolare la somma e la differenza. |
I modelli esistenti costruiti per questi compiti si basavano sull’integrazione delle informazioni di riconoscimento ottico dei caratteri (OCR) e delle loro coordinate in pipeline più ampie, ma il processo è soggetto a errori, lento e generalizza male. La prevalenza di questi metodi era dovuta al fatto che i modelli di visione artificiale end-to-end esistenti basati su reti neurali convoluzionali (CNN) o trasformatori pre-addestrati su immagini naturali non potevano essere facilmente adattati al linguaggio visuale. Ma i modelli esistenti non sono preparati alle sfide del rispondere alle domande su grafici, tra cui la lettura dell’altezza relativa delle barre o l’angolo delle fette nei grafici a torta, la comprensione delle scale degli assi, la mappatura corretta dei pictogrammi con i loro valori di legenda con colori, dimensioni e texture e infine l’esecuzione di operazioni numeriche con i numeri estratti.
- Preparazione pre-avanzata di visual-language potenziata dal recupero
- AVFormer Iniettare la visione in modelli di discorso congelati per l’AV-ASR senza sforzo
- Sottotitoli visivi Utilizzo di grandi modelli linguistici per arricchire le videoconferenze con immagini dinamiche.
Di fronte a queste sfide, proponiamo “MatCha: migliorare il pretraining del linguaggio visuale con il ragionamento matematico e la de-renderizzazione di grafici”. MatCha, che sta per matematica e grafici, è un modello fondamentale da pixel a testo (un modello pre-addestrato con bias induttivi integrati che può essere raffinato per molteplici applicazioni) addestrato su due compiti complementari: (a) de-renderizzazione di grafici e (b) ragionamento matematico. Nella de-renderizzazione di grafici, dato un plot o un grafico, il modello immagine-testo deve generare la sua tabella di dati sottostante o il codice usato per renderizzarlo. Per il pre-addestramento del ragionamento matematico, scegliamo set di dati di ragionamento numerico testuale e rendiamo l’input in immagini, che il modello immagine-testo deve decodificare per le risposte. Proponiamo anche “DePlot: ragionamento visuale del linguaggio in una sola volta tramite la traduzione da grafico a tabella”, un modello costruito su MatCha per il ragionamento in una sola volta sui grafici tramite la traduzione in tabelle. Con questi metodi superiamo lo stato dell’arte precedente in ChartQA di oltre il 20% e corrispondiamo ai migliori sistemi di sintesi che hanno 1000 volte più parametri. Entrambi i paper verranno presentati a ACL2023.
De-renderizzazione di grafici
I grafici e i diagrammi sono di solito generati da una tabella di dati sottostante e da un pezzo di codice. Il codice definisce la disposizione complessiva della figura (ad esempio, tipo, direzione, schema di colore/forma) e la tabella di dati sottostante stabilisce i numeri effettivi e i loro raggruppamenti. Sia i dati che il codice vengono inviati a un compilatore/motore di rendering per creare l’immagine finale. Per comprendere un grafico, è necessario scoprire i modelli visivi nell’immagine e analizzarli efficacemente per estrarre le informazioni chiave. Invertire il processo di rendering del grafico richiede tutte queste capacità e può quindi servire come compito di pre-addestramento ideale.
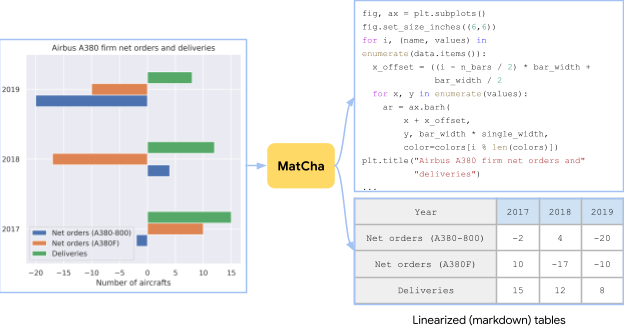 |
| Un grafico creato da una tabella nella pagina Wikipedia dell’Airbus A380 utilizzando opzioni di tracciamento casuali. Il compito di preformazione per MatCha consiste nel recuperare la tabella di origine o il codice di origine dall’immagine. |
Nella pratica, è difficile ottenere contemporaneamente grafici, le loro tabelle di dati sottostanti e il loro codice di rendering. Per raccogliere dati sufficienti per la preformazione, accumuliamo indipendentemente coppie [grafico, codice] e [grafico, tabella]. Per [grafico, codice], rastrelliamo tutti i notebook IPython di GitHub con le licenze appropriate ed estraiamo i blocchi con le figure. Una figura e il blocco di codice subito prima di essa vengono salvati come coppia [grafico, codice]. Per le coppie [grafico, tabella], abbiamo esplorato due fonti. Per la prima fonte, i dati sintetici, scriviamo manualmente il codice per convertire le tabelle di Wikipedia raccolte dal codice TaPas in grafici. Abbiamo campionato e combinato diverse opzioni di tracciamento a seconda dei tipi di colonne. Inoltre, aggiungiamo anche coppie [grafico, tabella] generate in PlotQA per diversificare il corpus di preformazione. La seconda fonte sono le coppie [grafico, tabella] rastrellate. Utilizziamo direttamente le coppie [grafico, tabella] raccolte nell’insieme di addestramento ChartQA, contenente circa 20k coppie in totale da quattro siti web: Statista, Pew, Our World in Data e OECD.
Ragionamento matematico
Incorporiamo conoscenze di ragionamento numerico in MatCha apprendendo abilità di ragionamento matematico da dataset matematici testuali. Utilizziamo due dataset di ragionamento matematico testuali esistenti, MATH e DROP per la preformazione. MATH è sinteticamente creato, contenente due milioni di esempi di addestramento per modulo (tipo) di domande. DROP è un dataset di QA in stile comprensione della lettura in cui l’input è un contesto di paragrafo e una domanda.
Per risolvere le domande in DROP, il modello deve leggere il paragrafo, estrarre i numeri pertinenti ed eseguire il calcolo numerico. Abbiamo trovato entrambi i dataset complementari. MATH contiene un gran numero di domande in diverse categorie, il che ci aiuta a identificare le operazioni matematiche necessarie da iniettare esplicitamente nel modello. Il formato di comprensione della lettura di DROP somiglia al formato QA tipico in cui i modelli eseguono simultaneamente l’estrazione di informazioni e il ragionamento. Nella pratica, rendiamo in immagini gli input di entrambi i dataset. Il modello è addestrato a decodificare la risposta.
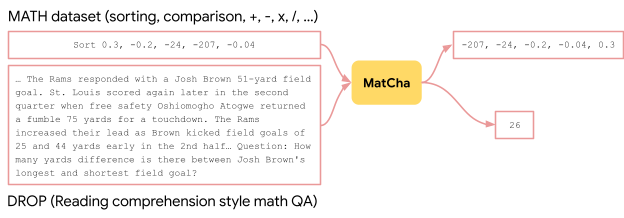 |
| Per migliorare le abilità di ragionamento matematico di MatCha, incorporiamo esempi da MATH e DROP nell’obiettivo di preformazione, rendendo il testo di input come immagini. |
Risultati end-to-end
Utilizziamo una struttura di modello Pix2Struct, che è un trasformatore di immagini in testo personalizzato per la comprensione dei siti web, e la preformiamo con i due compiti descritti sopra. Dimostriamo i punti di forza di MatCha per la messa a punto sulla diversi compiti di linguaggio visivo – compiti che coinvolgono grafici e plot per la risposta alle domande e la sintesi in cui non è possibile accedere alla tabella sottostante. MatCha supera le prestazioni dei modelli precedenti di gran lunga e supera anche lo stato dell’arte precedente, che presuppone l’accesso alle tabelle sottostanti.
Nella figura qui sotto, valutiamo prima due modelli di base che incorporano informazioni da una pipeline OCR, che fino a poco tempo fa era l’approccio standard per lavorare con i grafici. Il primo si basa su T5, il secondo su VisionTaPas. Confrontiamo anche con PaLI-17B, che è un grande trasformatore immagine più testo-a-testo (~1000 volte più grande degli altri modelli) addestrato su un insieme diversificato di compiti ma con capacità limitate per la lettura del testo e altre forme di linguaggio visivo. Infine, riportiamo i risultati dei modelli Pix2Struct e MatCha.
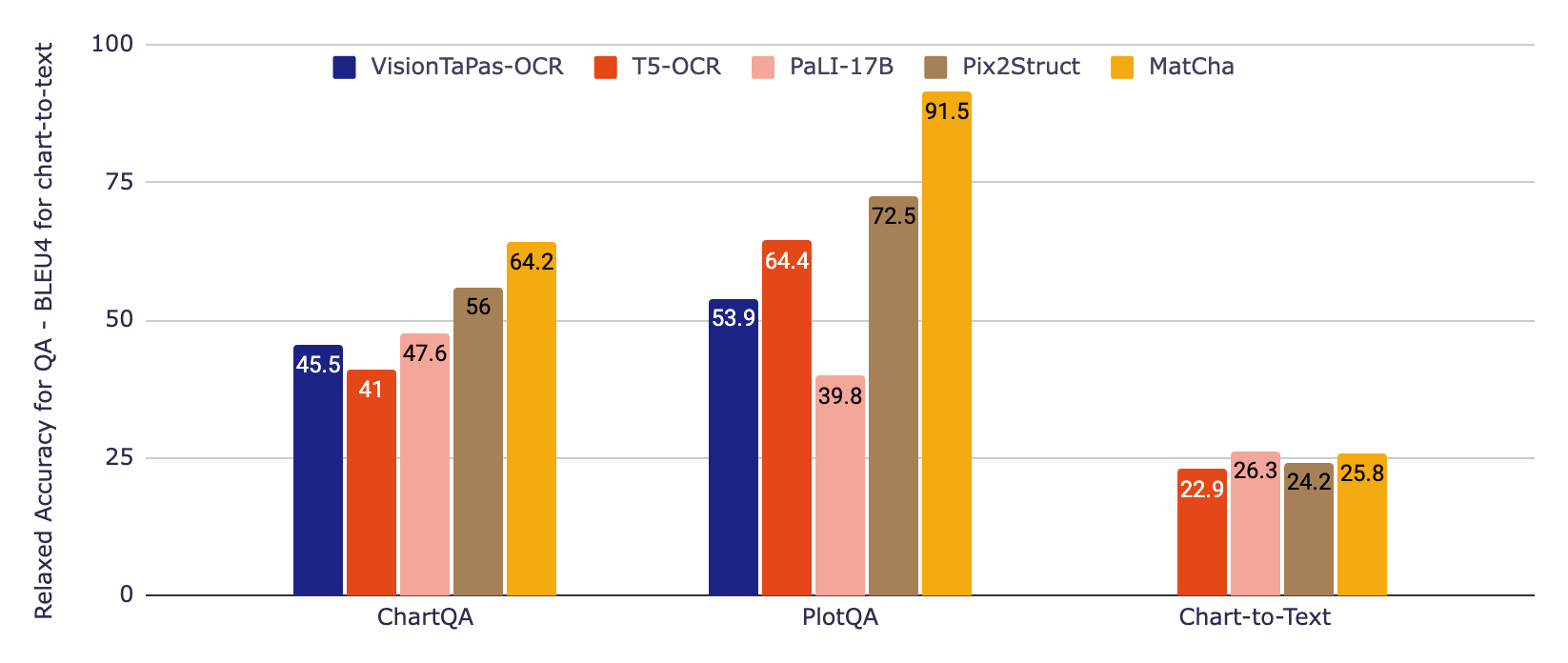 |
| Risultati sperimentali su due benchmark di QA per grafici ChartQA e PlotQA (usando l’accuratezza rilassata) e un benchmark di sintesi di grafici in testo chart-to-text (usando i punteggi BLEU4). MatCha supera di gran lunga lo stato dell’arte su QA, rispetto ai modelli più grandi, e si confronta con questi modelli più grandi sulla sintesi. |
Per i dataset di QA, usiamo la metrica ufficiale di accuratezza rilassata che consente piccoli errori relativi nelle uscite numeriche. Per la sintesi di grafici in testo, riportiamo i punteggi BLEU. MatCha raggiunge risultati notevolmente migliorati rispetto alle basi per la risposta alle domande e risultati comparabili a PaLI nella sintesi, dove la grande dimensione e l’ampio pre-addestramento per la generazione di testo a lunghezza estesa / didascalie sono vantaggiosi per questo tipo di generazione di testo a lunghezza estesa.
Catene di modelli di grandi linguaggi più de-rendering
Pur essendo estremamente performanti per il loro numero di parametri, in particolare per i compiti estrattivi, abbiamo osservato che i modelli MatCha ottimizzati potevano ancora avere difficoltà con il ragionamento complesso end-to-end (ad es. operazioni matematiche che coinvolgono grandi numeri o più passaggi). Pertanto, proponiamo anche un metodo a due fasi per affrontare questo problema: 1) un modello legge un grafico, quindi produce la tabella sottostante, 2) un grande modello di linguaggio (LLM) legge questa uscita e poi cerca di rispondere alla domanda esclusivamente basandosi sull’input testuale.
Per il primo modello, abbiamo ottimizzato MatCha esclusivamente per il compito di grafico-a-tabella, aumentando la lunghezza della sequenza di output per garantire che possa recuperare tutte o la maggior parte delle informazioni nel grafico. DePlot è il modello risultante. Nella seconda fase, qualsiasi LLM (come FlanPaLM o Codex) può essere utilizzato per il compito, e possiamo fare affidamento sui metodi standard per aumentare le prestazioni sui LLM, ad esempio chain-of-thought e self-consistency. Abbiamo anche sperimentato con programmi di pensiero in cui il modello produce codice Python eseguibile per alleggerire i calcoli complessi.
 |
| Un’illustrazione del metodo DePlot + LLM. Questo è un esempio reale che utilizza FlanPaLM e Codex. Le caselle blu sono input per il LLM e le caselle rosse contengono la risposta generata dai LLM. Evidenziamo alcuni dei passaggi di ragionamento chiave in ciascuna risposta. |
Come mostrato nell’esempio sopra, il modello DePlot in combinazione con LLM supera i modelli ottimizzati di gran lunga, soprattutto nella parte di ChartQA di origine umana, dove le domande sono più naturali ma richiedono un ragionamento più difficile. Inoltre, DePlot + LLM può farlo senza accedere a dati di addestramento.
Abbiamo rilasciato i nuovi modelli e il codice nel nostro repository GitHub, dove potete provarli voi stessi su Colab. Consultate i documenti su MatCha e DePlot per maggiori dettagli sui risultati sperimentali. Speriamo che i nostri risultati possano beneficiare la comunità di ricerca e rendere le informazioni contenute nei grafici e nei plot più accessibili a tutti.
Riconoscimenti
Questo lavoro è stato svolto da Fangyu Liu, Julian Martin Eisenschlos, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Wenhu Chen e Yasemin Altun del nostro Team Linguistico come parte del progetto di stage di Fangyu. Nigel Collier di Cambridge è stato anche un collaboratore. Vorremmo ringraziare Joshua Howland, Alex Polozov, Shrestha Basu Mallick, Massimo Nicosia e William Cohen per i loro preziosi commenti e suggerimenti.


