AWS Inferentia2 si basa su AWS Inferentia1 offrendo un throughput 4 volte superiore e una latenza 10 volte inferiore.
AWS Inferentia2 offre un throughput 4 volte superiore e una latenza 10 volte inferiore rispetto ad AWS Inferentia1.
Le dimensioni dei modelli di machine learning (ML) – grandi modelli di lingua (LLM) e modelli fondamentali (FM) – stanno crescendo rapidamente di anno in anno e questi modelli necessitano di acceleratori più veloci e potenti, soprattutto per l’AI generativa. AWS Inferentia2 è stato progettato fin dall’inizio per offrire prestazioni più elevate riducendo i costi di LLM e inferenza di IA generativa.
In questo post, mostreremo come la seconda generazione di AWS Inferentia si basa sulle capacità introdotte con AWS Inferentia1 e soddisfa le esigenze uniche di distribuzione e gestione di LLM e FM.
La prima generazione di AWS Inferentia, un acceleratore appositamente progettato lanciato nel 2019, è ottimizzato per accelerare l’inferenza di deep learning. AWS Inferentia ha aiutato gli utenti di ML a ridurre i costi di inferenza e migliorare la loro velocità di previsione e latenza. Con AWS Inferentia1, i clienti hanno visto un aumento fino al 2,3x della velocità di previsione e una riduzione fino al 70% del costo per inferenza rispetto alle istanze di Amazon Elastic Compute Cloud (Amazon EC2) ottimizzate per l’inferenza comparabili.
AWS Inferentia2, presente nelle nuove istanze Amazon EC2 Inf2 e supportato in Amazon SageMaker, è ottimizzato per l’inferenza di IA generativa su larga scala ed è la prima istanza di AWS focalizzata sull’inferenza ottimizzata per la distribuzione, con connettività ad alta velocità e bassa latenza tra gli acceleratori.
- Editor di Immagini e EditBench Avanzamento ed valutazione della riparazione delle immagini guidata dal testo.
- Hello world!
Ora puoi distribuire efficientemente un modello di 175 miliardi di parametri per l’inferenza su più acceleratori su una singola istanza Inf2 senza richiedere costose istanze di formazione. Fino ad oggi, i clienti che avevano grandi modelli potevano utilizzare solo istanze costruite per la formazione, ma questo è uno spreco di risorse, dato che sono più costose, consumano più energia e il loro carico di lavoro non sfrutta tutte le risorse disponibili (come la rete e lo storage più veloci). Con AWS Inferentia2, puoi ottenere una velocità di previsione 4 volte superiore e una latenza fino a 10 volte inferiore rispetto ad AWS Inferentia1. Inoltre, la seconda generazione di AWS Inferentia aggiunge un supporto migliorato per più tipi di dati, operatori personalizzati, tensori dinamici e altro ancora.
AWS Inferentia2 ha 4 volte più capacità di memoria, un’ampiezza di banda di memoria 16,4 volte superiore rispetto ad AWS Inferentia1 e supporto nativo per lo sharding di grandi modelli su più acceleratori. Gli acceleratori utilizzano NeuronLink e Neuron Collective Communication per massimizzare la velocità di trasferimento dei dati tra di loro o tra un acceleratore e l’adattatore di rete. AWS Inferentia2 è più adatto per modelli più grandi, che richiedono lo sharding su più acceleratori, anche se AWS Inferentia1 è ancora una grande opzione per modelli più piccoli perché fornisce una migliore performance-prezzo rispetto alle alternative.
Evoluzione dell’architettura
Per confrontare entrambe le generazioni di AWS Inferentia, rivediamo l’architettura di AWS Inferentia1. Ha quattro NeuronCores v1 per chip, mostrati nel diagramma seguente.

Specifiche per chip:
- Calcolo – Quattro core che forniscono in totale 128 INT8 TOPS e 64FP16/BF16 TFLOPS
- Memoria – 8 GB di DRAM (50 GB/sec di banda), condivisa da tutti e quattro i core
- NeuronLink – Link tra i core per lo sharding dei modelli su due o più core
Vediamo come è organizzato AWS Inferentia2. Ogni chip di AWS Inferentia2 ha due core aggiornati basati sull’architettura NeuronCore-v2. Come AWS Inferentia1, è possibile eseguire modelli diversi su ciascun NeuronCore o combinare più core per sharding grandi modelli.
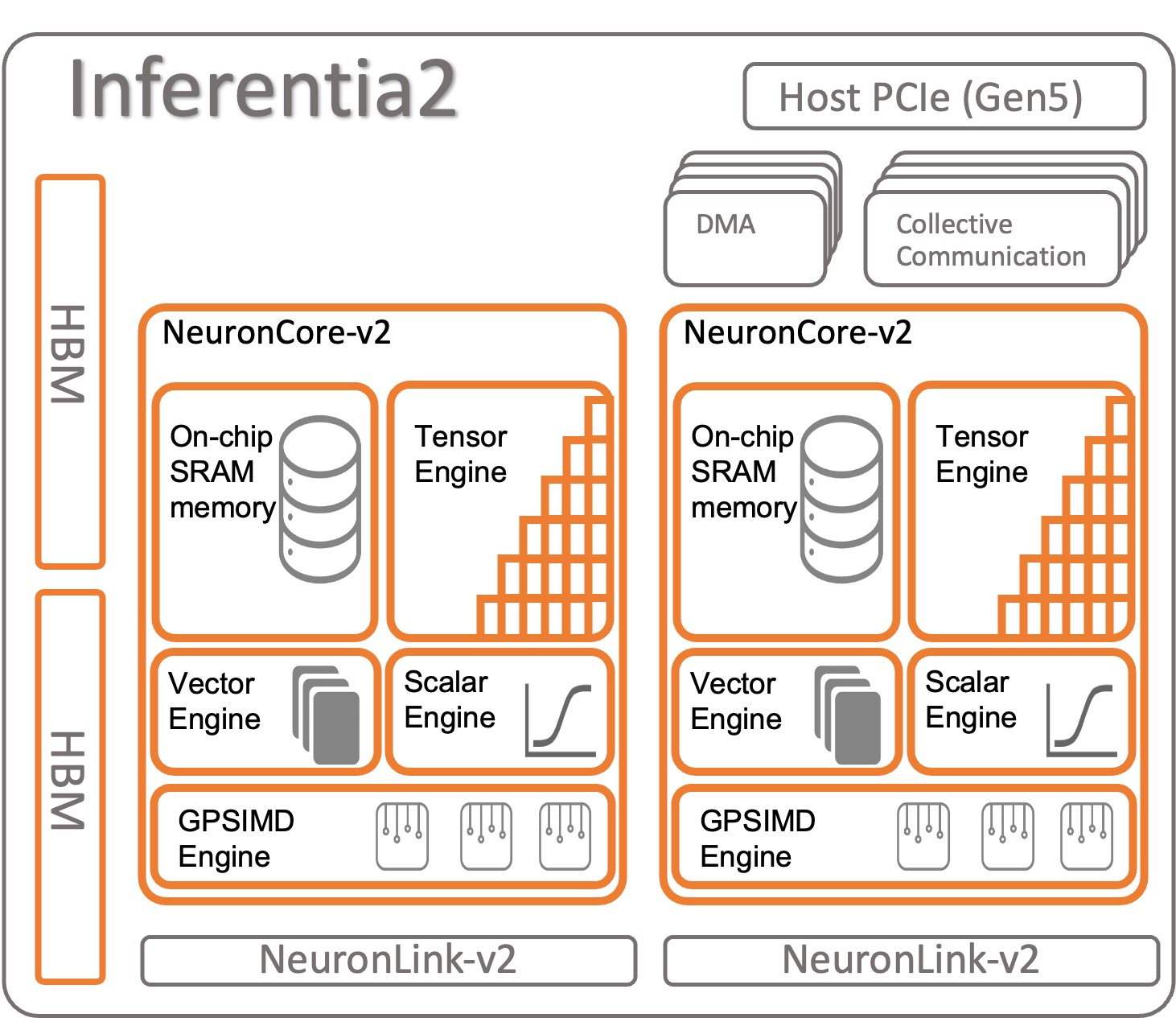
Specifiche per chip:
- Calcolo – Due core che forniscono in totale 380 INT8 TOPS, 190 FP16/BF16/cFP8/TF32 TFLOPS e 47,5 FP32 TFLOPS
- Memoria – 32 GB di HBM, condivisi da entrambi i core
- NeuronLink – Link tra i chip (384 GB/sec per dispositivo) per lo sharding dei modelli su due o più core
NeuronCore-v2 ha un design modulare con quattro motori indipendenti :
- ScalarEngine (3 volte più veloce di v1) – Opera su numeri in virgola mobile – 1600 (BF16/FP16) FLOPS
- VectorEngine (10 volte più veloce di v1) – Opera su vettori di numeri con una singola operazione per calcoli come la normalizzazione, il pooling e altri.
- TensorEngine (6 volte più veloce di v1) – Esegue calcoli tensoriali come Conv, Reshape, Transpose e altri.
- GPSIMD-Engine – Ha otto processori programmabili completamente a 512 bit di larghezza a uso generale per creare operatori personalizzati con l’API degli operatori C++ personalizzati standard di PyTorch. Si tratta di una nuova funzionalità introdotta in NeuronCore-v2.
AWS Inferentia2 NeuronCore-v2 è più veloce e ottimizzato. Inoltre, è in grado di accelerare diversi tipi e dimensioni di modelli, che vanno dai modelli semplici come ResNet 50 a modelli di lingua più grandi o modelli fondamentali con miliardi di parametri come GPT-3 (175 miliardi di parametri). AWS Inferentia2 ha anche una memoria interna più grande e veloce, rispetto ad AWS Inferentia1, come mostrato nella seguente tabella.
| Chip | Neuron Cores | Tipo di memoria | Dimensione della memoria | Banda della memoria |
| AWS Inferentia | x4 (v1) | DDR4 | 8GB | 50GB/S |
| AWS Inferentia 2 | x2 (v2) | HBM | 32GB | 820GB/S |
La memoria che trovi in AWS Inferentia2 è del tipo High-Bandwidth Memory (HBM). Ogni chip AWS Inferentia2 ha 32 GB e può essere combinato con altri chip per distribuire modelli molto grandi usando NeuronLink (interconnessione dispositivo-dispositivo). Un inf2.48xlarge, ad esempio, ha 12 acceleratori AWS Inferentia2 con un totale di 384 GB di memoria accelerata. La velocità della memoria di AWS Inferentia2 è 16,4 volte più veloce di AWS Inferentia1, come mostrato nella tabella precedente.
Altre funzionalità
AWS Inferentia2 offre le seguenti funzionalità aggiuntive:
- Hardware supportato – cFP8 (nuovo, FP8 configurabile), FP16, BF16, TF32, FP32, INT8, INT16 e INT32. Per ulteriori informazioni, vedere Tipi di dati.
- Inferenza Lazy Tensor – Discutiamo l’inferenza Lazy Tensor in seguito in questo post.
- Operatori personalizzati – Gli sviluppatori possono utilizzare le interfacce di programmazione degli operatori personalizzati standard di PyTorch per utilizzare la funzione Custom C++ Operators. Un operatore personalizzato è composto da primitive a basso livello disponibili nelle funzioni della fabbrica di tensori e accelerate da GPSIMD-Engine.
- Controllo del flusso (in arrivo) – Questo è per il flusso di controllo del linguaggio di programmazione nativo all’interno del modello per eventualmente preprocessare e postprocessare i dati da un layer all’altro.
- Dynamic-shapes (in arrivo) – Questo è utile quando il tuo modello modifica la forma dell’output di qualsiasi layer interno dinamicamente. Per esempio: un filtro che riduce la dimensione o la forma del tensore di output all’interno del modello, sulla base dei dati in ingresso.
Accelerazione dei modelli su AWS Inferentia1 e AWS Inferentia2
L’AWS Neuron SDK viene utilizzato per compilare ed eseguire il tuo modello. È integrato nativamente con PyTorch e TensorFlow. In questo modo, non è necessario eseguire un altro strumento. Utilizza il tuo codice originale, scritto in uno di questi framework di ML, e con poche righe di modifiche del codice, sei pronto per AWS Inferentia.
Vediamo come compilare ed eseguire un modello su AWS Inferentia1 e AWS Inferentia2 utilizzando PyTorch.
Caricare un modello pre-addestrato (ResNet 50) da torchvision
Caricare un modello pre-addestrato ed eseguirlo una volta per scaldarlo:
import torch
import torchvision
model = torchvision.models.resnet50(weights='IMAGENET1K_V1').eval().cpu()
x = torch.rand(1,3,224,224).float().cpu() # input fittizio
y = model(x) # scaldamento del modelloTracciare e distribuire il modello accelerato su Inferentia1
Per tracciare il modello su AWS Inferentia, importare torch_neuron e invocare la funzione di tracciamento. Ricordare che il modello deve essere tracciabile con PyTorch Jit per funzionare.
Alla fine del processo di tracciamento, salvare il modello come un normale modello PyTorch. Compilare il modello una volta e caricarlo tutte le volte che serve. La runtime della Neuron SDK è già integrata in PyTorch e si occupa di inviare automaticamente gli operatori al chip AWS Inferentia1 per accelerare il modello.
Nel codice di inferenza, è sempre necessario importare torch_neuron per attivare la runtime integrata.
È possibile passare parametri aggiuntivi al compilatore per personalizzare il modo in cui ottimizza il modello o per abilitare funzionalità speciali come neuron-pipeline-cores. Suddividere il modello su più core per aumentare il throughput.
import torch_neuron
# Tracciamento del modello utilizzando la NeuronSDK di AWS
neuron_model = torch_neuron.trace(model,x) # traccia il modello su Inferentia
# Salvataggio per uso futuro
neuron_model.save('neuron_resnet50.pt')
# La prossima volta non è necessario tracciare nuovamente il modello
# Basta caricarlo e AWS NeuronSDK lo invierà ad Inferentia automaticamente
neuron_model = torch.jit.load('neuron_resnet50.pt')
# Inferenza accelerata su Inferentia
y = neuron_model(x)Tracciare e distribuire il modello accelerato su Inferentia2
Per AWS Inferentia2, il processo è simile. L’unica differenza è il pacchetto che si importa termina con x: torch_neuronx . La Neuron SDK si occupa della compilazione e dell’esecuzione del modello per te in modo trasparente. È possibile passare anche parametri aggiuntivi al compilatore per perfezionare l’operazione o attivare funzionalità specifiche.
import torch_neuronx
# Tracciamento del modello utilizzando NeuronSDK
neuron_model = torch_neuronx.trace(model,x) # traccia il modello su Inferentia
# Salvataggio per uso futuro
neuron_model.save('neuron_resnet50.pt')
# La prossima volta non è necessario tracciare nuovamente il modello
# Basta caricarlo e NeuronSDK lo invierà ad Inferentia automaticamente
neuron_model = torch.jit.load('neuron_resnet50.pt')
# Inferenza accelerata su Inferentia
y = neuron_model(x)AWS Inferentia2 offre anche un secondo approccio per l’esecuzione di un modello chiamato Lazy Tensor inference . In questa modalità, non si traccia o si compila il modello in precedenza; invece, il compilatore viene eseguito al volo ogni volta che si esegue il codice. Non è consigliato per la produzione, dato che la modalità tracciata ha molti vantaggi rispetto alla Lazy Tensor inference. Tuttavia, se si sta ancora sviluppando il modello e si ha bisogno di testarlo più rapidamente, la Lazy Tensor inference può essere una buona alternativa. Ecco come compilare ed eseguire un modello utilizzando la Lazy Tensor:
import torch
import torchvision
import torch_neuronx
import torch_xla.core.xla_model as xm
device = xm.xla_device() # Creazione dispositivo XLA
model = torchvision.models.resnet50(weights='IMAGENET1K_V1').eval().cpu()
model.to(device)
x = torch.rand((1,3,224,224), device=device) # input fittizio
with torch.no_grad():
y = model(x)
xm.mark_step() # La compilazione avviene quiOra che si è familiarizzati con AWS Inferentia2, un buon passo successivo è iniziare con PyTorch o Tensorflow e imparare come configurare un ambiente di sviluppo ed eseguire tutorial ed esempi. Inoltre, controllare il repository GitHub di AWS Neuron Samples , dove è possibile trovare diversi esempi su come preparare i modelli per l’esecuzione su Inf2, Inf1 e Trn1.
Riassunto del confronto tra le caratteristiche di AWS Inferentia1 e AWS Inferentia2
Il compilatore AWS Inferentia2 è basato su XLA e AWS fa parte dell’iniziativa OpenXLA. Questa è la differenza più grande rispetto ad AWS Inferentia1 ed è rilevante perché PyTorch, TensorFlow e JAX hanno integrazioni native di XLA. XLA porta molti miglioramenti delle prestazioni, dato che ottimizza il grafico per calcolare i risultati in un singolo lancio del kernel. Fonde tra loro le operazioni tensoriali successive e produce codice macchina ottimale per accelerare l’esecuzione del modello su AWS Inferentia2. Altre parti dell’SDK Neuron sono state migliorate anche in AWS Inferentia2, mantenendo l’esperienza utente il più semplice possibile durante la tracciatura e l’esecuzione dei modelli. La seguente tabella mostra le funzionalità disponibili in entrambe le versioni del compilatore e dell’ambiente di esecuzione.
| Funzionalità | torch-neuron | torch-neuronx |
| Tensorboard | Sì | Sì |
| Istanze supportate | Inf1 | Inf2 & Trn1 |
| Supporto all’Inference | Sì | Sì |
| Supporto alla formazione | No | Sì |
| Architettura | NeuronCore-v1 | NeuronCore-v2 |
| Trace API | torch_neuron.trace() | torch_neuronx.trace() |
| Inference distribuito | Pipeline NeuronCore | Comunicazioni collettive |
| IR | GraphDef | HLO |
| Compilatore | neuron-cc | neuronx-cc |
| Monitoraggio | neuron-monitor / monitor-top | neuron-monitor / monitor-top |
Per un confronto più dettagliato tra torch-neuron (Inf1) e torch-neuronx (Inf2 & Trn1), fare riferimento al Confronto di torch-neuron (Inf1) versus torch-neuronx (Inf2 & Trn1) per Inference.
Servizio di modelli
Dopo aver tracciato un modello per il deploy su Inf2, si hanno molte opzioni di deploy. È possibile eseguire previsioni in tempo reale o previsioni batch in modi diversi. Inf2 è disponibile perché le istanze EC2 sono integrate nativamente con altri servizi AWS che utilizzano i contenitori di deep learning (DLC) come Amazon Elastic Container Service (Amazon ECS), Amazon Elastic Kubernetes Service (Amazon EKS) e SageMaker.
AWS Inferentia2 è compatibile con le tecnologie di deploy più popolari. Ecco un elenco di alcune delle opzioni che si hanno per il deploy di modelli utilizzando AWS Inferentia2:
- SageMaker – Servizio completamente gestito per la preparazione dei dati e la creazione, formazione e distribuzione di modelli ML
- TorchServe – Meccanismo di deploy integrato di PyTorch
- TensorFlow Serving – Meccanismo di deploy integrato di TensorFlow
- Deep Java Library – Meccanismo open-source di Java per il deploy e la formazione di modelli
- Triton – Servizio open-source NVIDIA per il deploy di modelli
Benchmark
La seguente tabella evidenzia i miglioramenti che AWS Inferentia2 apporta rispetto ad AWS Inferentia1. In particolare, misuriamo la latenza (quanto velocemente il modello può fare una previsione utilizzando ogni acceleratore), il throughput (quante inferenze al secondo) e il costo per inferenza (quanto costa ogni inferenza in dollari statunitensi). Più bassa è la latenza in millisecondi e i costi in dollari statunitensi, meglio è. Più è alto il throughput, meglio è.
In questo processo sono stati utilizzati due modelli – entrambi grandi modelli di lingua: ELECTRA large discriminator e BERT large uncased. PyTorch (1.13.1) e Hugging Face transformers (v4.7.0), le principali librerie utilizzate in questo esperimento, sono stati eseguiti su Python 3.8. Dopo aver compilato i modelli per batch size = 1 e 10 (utilizzando il codice della sezione precedente come riferimento), ogni modello è stato riscaldato (invocato una volta per inizializzare il contesto) e poi invocato 10 volte di seguito. La seguente tabella mostra i numeri medi raccolti in questo semplice benchmark.
- Electra large discriminator (334.092.288 parametri ~593 MB)
- Bert large uncased (335.143.938 parametri ~580 MB)
- OPT-66B (66 miliardi di parametri ~124 GB)
| Nome del Modello | Batch Size | Lunghezza della frase | Latenza (ms) | Miglioramenti Inf2 su Inf1 (volte x) | Throughput (Inferenze al secondo) | Costo per Inferenza (EC2 us-east-1) ** | |||
| Inf1 | Inf2 | Inf1 | Inf2 | Inf1 | Inf2 | ||||
| ElectraLargeDiscriminator | 1 | 256 | 35,7 | 8,31 | 4,30 | 28,01 | 120,34 | $0,0000023 | $0,0000018 |
| ElectraLargeDiscriminator | 10 | 256 | 343,7 | 72,9 | 4,71 | 2,91 | 13,72 | $0,0000022 | $0,0000015 |
| BertLargeUncased | 1 | 128 | 28,2 | 3,1 | 9,10 | 35,46 | 322,58 | $0,0000018 | $0,0000007 |
| BertLargeUncased | 10 | 128 | 121,1 | 23,6 | 5,13 | 8,26 | 42,37 | $0,0000008 | $0,0000005 |
* c6a.8xlarge con 32 CPU AMD Epyc 7313 è stato utilizzato in questo benchmark.
** Prezzo pubblico EC2 in us-east-1 il 20 aprile: inf2.xlarge: $0.7582/h; inf1.xlarge: $0.228/h. Il costo per inferenza considera il costo per elemento in un batch. (Il costo per inferenza equivale al costo totale dell’invocazione del modello/dimensione del batch.)
Per ulteriori informazioni sulle prestazioni di addestramento e inferenza, fare riferimento a Prestazioni Trn1/Trn1n.
Conclusioni
AWS Inferentia2 è una potente tecnologia progettata per migliorare le prestazioni e ridurre i costi dell’inferenza dei modelli di deep learning. Più performante di AWS Inferentia1, offre un throughput fino a 4 volte superiore, una latenza fino a 10 volte inferiore e una prestazione/watt fino al 50% migliore rispetto ad altre istanze EC2 ottimizzate per l’inferenza comparabili. Alla fine, si paga meno, si ha un’applicazione più veloce e si raggiungono gli obiettivi di sostenibilità.
È semplice e diretto migrare il codice di inferenza su AWS Inferentia2, che supporta anche una maggiore varietà di modelli, inclusi i grandi modelli linguistici e i modelli fondamentali per l’AI generativa.
È possibile iniziare seguendo la documentazione AWS Neuron SDK per configurare un ambiente di sviluppo e avviare il proprio progetto di deep learning accelerato. Per aiutarti ad iniziare, Hugging Face ha aggiunto il supporto di Neuron alla loro libreria Optimum, che ottimizza i modelli per un addestramento e un’infereza più veloci, e hanno molti esempi di attività pronti per essere eseguiti su Inf2. Inoltre, controlla il nostro Deploy large language models on AWS Inferentia2 using large model inference containers per saperne di più sulla distribuzione di LLM su AWS Inferentia2 utilizzando i contenitori di inferenza del modello. Per ulteriori esempi, vedere il repo di campioni AWS Neuron su GitHub.
