Barkour Misurare le capacità di agilità a livello animale con robot quadrupedi
Assess animal agility with quadruped robots - Barkour.
Pubblicato da Ken Caluwaerts e Atil Iscen, Scienziati della Ricerca, Google
Creare robot che mostrino capacità di locomozione robuste e dinamiche, simili ad animali o esseri umani, è stato un obiettivo a lungo termine nella comunità della robotica. Oltre a completare le attività in modo rapido ed efficiente, l’agilità consente ai robot con gambe di muoversi attraverso ambienti complessi altrimenti difficili da attraversare. I ricercatori di Google hanno cercato l’agilità per diversi anni e su varie forme. Tuttavia, sebbene i ricercatori abbiano permesso ai robot di fare escursioni o saltare alcuni ostacoli, non esiste ancora un benchmark generalmente accettato che misuri in modo esaustivo l’agilità o la mobilità dei robot. Al contrario, i benchmark sono forze trainanti dietro lo sviluppo dell’apprendimento automatico, come ImageNet per la visione artificiale e OpenAI Gym per l’apprendimento per rinforzo (RL).
In “Barkour: Benchmarking Animal-level Agility with Quadruped Robots”, presentiamo il benchmark di agilità Barkour per robot a quattro zampe, insieme a una politica di locomozione generalista basata su Transformer. Ispirandoci alle competizioni di agilità dei cani, un robot con gambe deve mostrare sequenzialmente una varietà di abilità, inclusi il movimento in diverse direzioni, il superamento di terreni diseguali e il salto di ostacoli entro un tempo limitato per completare con successo il benchmark. Fornendo un percorso ostacolato vario e impegnativo, il benchmark Barkour incentiva i ricercatori a sviluppare controller di locomozione che si muovono rapidamente in modo controllabile e versatile. Inoltre, legando la metrica delle prestazioni alla prestazione dei cani reali, forniamo una metrica intuitiva per comprendere le prestazioni del robot rispetto ai loro omologhi animali.
| Abbiamo invitato alcuni “dooglers” a provare il percorso ostacolato per assicurarci che i nostri obiettivi di agilità fossero realistici e impegnativi. I cani di piccola taglia completano il percorso ostacolato in circa 10 secondi, mentre le prestazioni tipiche dei nostri robot si aggirano intorno ai 20 secondi. |
Benchmark Barkour
Il sistema di punteggio di Barkour utilizza un tempo obiettivo per ogni ostacolo e per l’intero percorso basato sulla velocità obiettivo dei cani di piccola taglia nelle competizioni di agilità per principianti (circa 1,7 m/s). I punteggi di Barkour vanno da 0 a 1, con 1 che corrisponde al robot che attraversa con successo tutti gli ostacoli lungo il percorso entro il tempo assegnato di circa 10 secondi, il tempo medio necessario per un cane di taglia simile per attraversare il percorso. Il robot riceve penalità per aver saltato, non aver superato gli ostacoli o per essersi mosso troppo lentamente.
- Modelli di base per il ragionamento sui grafici.
- Preparazione pre-avanzata di visual-language potenziata dal recupero
- AVFormer Iniettare la visione in modelli di discorso congelati per l’AV-ASR senza sforzo
Il nostro percorso standard consiste in quattro ostacoli unici in un’area di 5m x 5m. Questa è una configurazione più densa e più piccola rispetto a una tipica competizione di cani per consentire una facile distribuzione in un laboratorio di robotica. Iniziando dal tavolo di partenza, il robot deve intrecciarsi attraverso un insieme di pali, arrampicarsi su una rampa a forma di A, superare un salto largo 0,5 m e poi salire sul tavolo finale. Abbiamo scelto questo sottoinsieme di ostacoli perché testano un insieme diversificato di abilità mantenendo l’impostazione all’interno di una piccola area. Come avviene per le vere competizioni di agilità dei cani, il benchmark Barkour può essere facilmente adattato a una zona di percorso più grande e può incorporare un numero variabile di ostacoli e configurazioni del percorso.
 |
| Panoramica della configurazione del percorso ostacolato del benchmark Barkour, che consiste di pali intrecciati, una rampa a forma di A, un salto largo e tavoli di pausa. Il meccanismo di punteggio intuitivo, ispirato alle competizioni di agilità dei cani, bilancia la velocità, l’agilità e le prestazioni e può essere facilmente modificato per incorporare altri tipi di ostacoli o configurazioni del percorso. |
Apprendimento di abilità di locomozione agili
Il benchmark Barkour presenta un insieme di ostacoli diversificato e un sistema di ricompensa ritardato, che costituiscono una sfida significativa durante l’addestramento di una singola politica che possa completare l’intero percorso ostacolato. Quindi, al fine di impostare una forte linea di base delle prestazioni e dimostrare l’efficacia del benchmark per la ricerca sull’agilità dei robot, adottiamo un framework student-teacher combinato con un approccio sim-to-real a zero-shot. In primo luogo, addestriamo abilità di locomozione specialistica individuali (insegnante) per diversi ostacoli utilizzando metodi di RL in-policy. In particolare, sfruttiamo i recenti progressi nella simulazione parallela su larga scala per dotare il robot di abilità individuali, tra cui politiche di camminata, scalata di pendii e salti.
Successivamente, addestriamo una singola policy (student) che esegue tutte le abilità e le transizioni tra di esse utilizzando un framework student-teacher, basato sulle abilità specialistiche che abbiamo precedentemente addestrato. Utilizziamo rollouts di simulazione per creare dataset di coppie stato-azione per ciascuna delle abilità specialistiche. Questo dataset viene poi distillato in una singola policy di locomozione generalista basata su Transformer, che può gestire vari terreni e regolare la camminata del robot in base all’ambiente percepito e allo stato del robot.
 |
Durante la distribuzione, abbiniamo la policy di locomozione generalista in grado di eseguire molte abilità con un controller di navigazione che fornisce comandi di velocità sulla base della posizione del robot. La nostra policy addestrata controlla il robot in base all’ambiente circostante rappresentato come una mappa dell’elevazione, ai comandi di velocità e alle informazioni sensoriali a bordo fornite dal robot.
| Pipeline di distribuzione per l’architettura Transformer di locomozione. Al momento della distribuzione, un controller di navigazione ad alto livello guida il robot reale attraverso il percorso degli ostacoli inviando comandi alla policy di locomozione Transformer. |
La robustezza e la ripetibilità sono difficili da raggiungere quando si mira alle prestazioni massime e alla massima velocità. A volte, il robot potrebbe fallire nel superare un ostacolo in modo agile. Per gestire i fallimenti, addestriamo una policy di recupero che riporta rapidamente il robot in piedi, consentendogli di continuare l’episodio.
Valutazione
Valutiamo la policy di locomozione generalista basata su Transformer utilizzando robot quadrupedi costruiti su misura e dimostriamo che ottimizzando per la proposta di benchmark, otteniamo abilità agili, robuste e versatili per il nostro robot nel mondo reale. Inoltre, forniamo un’analisi per le varie scelte progettuali nel nostro sistema e il loro impatto sulle prestazioni del sistema.
 |
| Modello dei robot costruiti su misura utilizzati per la valutazione. |
Distribuiamo sia le policy specialistiche che generaliste sull’hardware (sim-to-real senza bisogno di addestramento). La traiettoria di destinazione del robot è fornita da un insieme di punti lungo i vari ostacoli. Nel caso delle policy specialistiche, passiamo da una policy all’altra utilizzando un meccanismo di commutazione della policy regolato manualmente che seleziona la policy più adatta data la posizione del robot.
| Prestazioni tipiche delle nostre policy di locomozione agili sul benchmark Barkour. Il nostro robot quadrupede costruito su misura naviga con robustezza gli ostacoli del terreno sfruttando varie abilità apprese mediante RL in simulazione. |
Troviamo che molto spesso le nostre policy possono gestire eventi imprevisti o anche la degradazione dell’hardware risultando in una buona performance media, ma i fallimenti sono ancora possibili. Come illustrato nell’immagine sottostante, in caso di fallimenti, la nostra policy di recupero riporta rapidamente il robot in piedi, consentendogli di continuare l’episodio. Combinando la policy di recupero con una semplice policy di cammino di ritorno all’inizio, siamo in grado di eseguire esperimenti ripetuti con un intervento umano minimo per misurare la robustezza.
| Esempio qualitativo di comportamenti robusti e di ripristino. Il robot inciampa e si ribalta dopo aver affrontato la A-frame. Ciò attiva la politica di ripristino, che consente al robot di rialzarsi e continuare il percorso. |
Troviamo che, in un gran numero di valutazioni, la singola politica generalista di trasformazione della locomozione e le politiche specialistiche con il meccanismo di commutazione della politica raggiungono prestazioni simili. La politica di trasformazione della locomozione ha un punteggio medio di Barkour leggermente più basso, ma mostra transizioni più fluide tra i comportamenti e le andature.
| Misurazione della robustezza delle diverse politiche in un gran numero di esecuzioni sul benchmark di Barkour. |
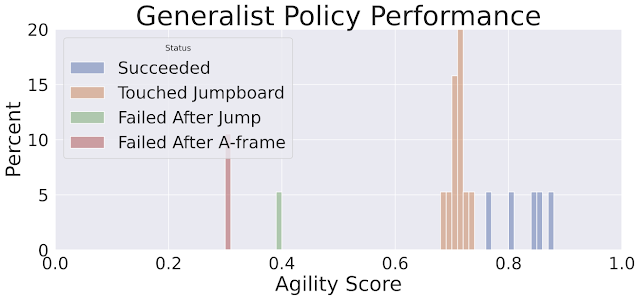 |
| Istogramma dei punteggi di agilità per la politica di trasformazione della locomozione. I punteggi più alti mostrati in blu (0,75 – 0,9) rappresentano le esecuzioni in cui il robot completa con successo tutti gli ostacoli. |
Conclusione
Riteniamo che lo sviluppo di un benchmark per la robotica a quattro zampe sia un importante primo passo nel quantificare i progressi verso l’agilità di livello animale. Per stabilire una solida base di riferimento, abbiamo studiato un approccio sim-to-real zero-shot, sfruttando la simulazione parallela su larga scala e i recenti progressi nella formazione di architetture basate su Transformer. I nostri risultati dimostrano che Barkour è un benchmark impegnativo che può essere facilmente personalizzato e che il nostro metodo di apprendimento per risolvere il benchmark fornisce a un robot quadrupede una singola politica a basso livello che può eseguire una varietà di abilità agili a basso livello.
Riconoscimenti
Gli autori di questo post fanno ora parte di Google DeepMind. Vorremmo ringraziare i nostri coautori di Google DeepMind e i nostri collaboratori di Google Research: Wenhao Yu, J. Chase Kew, Tingnan Zhang, Daniel Freeman, Kuang-Hei Lee, Lisa Lee, Stefano Saliceti, Vincent Zhuang, Nathan Batchelor, Steven Bohez, Federico Casarini, Jose Enrique Chen, Omar Cortes, Erwin Coumans, Adil Dostmohamed, Gabriel Dulac-Arnold, Alejandro Escontrela, Erik Frey, Roland Hafner, Deepali Jain, Yuheng Kuang, Edward Lee, Linda Luu, Ofir Nachum, Ken Oslund, Jason Powell, Diego Reyes, Francesco Romano, Feresteh Sadeghi, Ron Sloat, Baruch Tabanpour, Daniel Zheng, Michael Neunert, Raia Hadsell, Nicolas Heess, Francesco Nori, Jeff Seto, Carolina Parada, Vikas Sindhwani, Vincent Vanhoucke e Jie Tan. Vorremmo anche ringraziare Marissa Giustina, Ben Jyenis, Gus Kouretas, Nubby Lee, James Lubin, Sherry Moore, Thinh Nguyen, Krista Reymann, Satoshi Kataoka, Trish Blazina e i membri del team di robotica di Google DeepMind per il loro contributo al progetto. Grazie a John Guilyard per la creazione delle animazioni in questo post.



