Apprendimento automatico a effetti misti per variabili categoriche ad alta cardinalità — Parte I un confronto empirico di diversi metodi
Apprendimento automatico per variabili categoriche ad alta cardinalità un confronto empirico di metodi.
Perché gli effetti casuali sono utili per i modelli di apprendimento automatico
Le variabili categoriche ad alta cardinalità sono variabili per le quali il numero di livelli diversi è elevato rispetto alla dimensione del campione di un set di dati, o in altre parole, ci sono pochi punti dati per livello di una variabile categorica. I metodi di apprendimento automatico possono avere difficoltà con le variabili ad alta cardinalità. In questo articolo, sosteniamo che gli effetti casuali sono uno strumento efficace per modellare le variabili categoriche ad alta cardinalità nei modelli di apprendimento automatico. In particolare, confrontiamo empiricamente diverse versioni di due dei metodi di apprendimento automatico di maggior successo, il tree-boosting e le reti neurali profonde, nonché i modelli a effetti misti lineari utilizzando più set di dati tabulari con variabili categoriche ad alta cardinalità. I nostri risultati mostrano che, in primo luogo, i modelli di apprendimento automatico con effetti casuali hanno prestazioni migliori rispetto ai loro equivalenti senza effetti casuali, e, in secondo luogo, il tree-boosting con effetti casuali supera le reti neurali profonde con effetti casuali.
Indice
· 1 Introduzione · 2 Effetti casuali per la modellazione di variabili categoriche ad alta cardinalità · 3 Confronto tra diversi metodi utilizzando set di dati del mondo reale · 4 Conclusioni · Riferimenti
1 Introduzione
Una strategia semplice per gestire le variabili categoriche è utilizzare l’encoding one-hot o le variabili dummy. Ma questo approccio spesso non funziona bene per le variabili categoriche ad alta cardinalità a causa delle ragioni descritte di seguito. Per le reti neurali, una soluzione spesso adottata sono gli embedding di entità [Guo and Berkhahn, 2016] che mappano ogni livello di una variabile categorica in uno spazio euclideo a bassa dimensione. Per il tree-boosting, un approccio semplice è assegnare un numero a ogni livello di una variabile categorica e considerarlo come una variabile numerica unidimensionale. Una soluzione alternativa implementata nella libreria di boosting LightGBM [Ke et al., 2017] funziona partizionando tutti i livelli in due sottoinsiemi utilizzando un approccio approssimativo [Fisher, 1958] durante la ricerca delle suddivisioni nell’algoritmo di costruzione dell’albero. Inoltre, la libreria di boosting CatBoost [Prokhorenkova et al., 2018] implementa un approccio basato su statistiche target ordinate calcolate utilizzando partizioni casuali dei dati di addestramento per gestire le variabili predittive categoriche.
2 Effetti casuali per la modellazione di variabili categoriche ad alta cardinalità
Gli effetti casuali possono essere utilizzati come uno strumento efficace per modellare le variabili categoriche ad alta cardinalità. Nel caso della regressione con una singola variabile categorica ad alta cardinalità, un modello a effetti casuali può essere scritto come
- Gli scienziati del MIT costruiscono un sistema in grado di generare modelli di intelligenza artificiale per la ricerca biologica.
- Apprendere il linguaggio delle molecole per prevedere le loro proprietà
- Incontra JourneyDB un dataset di grandi dimensioni con 4 milioni di immagini diverse e di alta qualità generate, selezionate per la comprensione visiva multimodale.
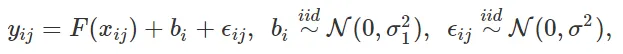
dove j=1,…,ni è l’indice del campione all’interno del livello i, con ni che rappresenta il numero di campioni per i quali la variabile categorica raggiunge il livello i, e i indica il livello con q che rappresenta il numero totale di livelli della variabile categorica. Il numero totale di campioni è quindi n = n0 + n1 + … + nq. Un tale modello è anche chiamato modello a effetti misti in quanto contiene sia effetti fissi F(xij) che effetti casuali bi. xij sono le variabili predittive o caratteristiche con effetti fissi. I modelli a effetti misti possono essere estesi ad altre distribuzioni di variabili di risposta (ad esempio, classificazione) e a più variabili categoriche.
Tradizionalmente, gli effetti casuali venivano utilizzati nei modelli lineari in cui si assumeva che F fosse una funzione lineare. Negli ultimi anni, i modelli a effetti misti lineari sono stati estesi a modelli non lineari utilizzando random forest [Hajjem et al., 2014], tree-boosting [Sigrist, 2022 , 2023a ], e più di recente (in termini di primo preprint pubblico) reti neurali profonde [Simchoni and Rosset, 2021 , 2023 ]. A differenza dei classici modelli di apprendimento automatico indipendenti, gli effetti casuali introducono dipendenza tra i campioni.
Perché gli effetti casuali sono utili per le variabili categoriali ad alta cardinalità?
Per le variabili categoriali ad alta cardinalità, ci sono pochi dati per ogni livello. Intuitivamente, se la variabile di risposta ha una media condizionata diversa per molti livelli, i modelli di machine learning tradizionali (con, ad esempio, one-hot encoding, embeddings o semplicemente variabili numeriche unidimensionali) possono avere problemi di sovra- o sotto-adattamento per tali dati. Dal punto di vista di un classico trade-off tra bias e varianza, i modelli di machine learning indipendenti possono avere difficoltà a bilanciare questo trade-off e a trovare una quantità appropriata di regolarizzazione. Ad esempio, può verificarsi un sovradattamento, il che significa che un modello ha un basso bias ma alta varianza.
In generale, gli effetti casuali agiscono come un prior, o regolarizzatore, che modella la parte difficile di una funzione, ovvero la parte il cui “dimensione” è simile alla dimensione totale del campione e, nel farlo, forniscono un modo efficace per trovare un equilibrio tra sovra- e sotto-adattamento o bias e varianza. Ad esempio, per una singola variabile categorica, i modelli a effetti casuali ridurranno le stime degli effetti di intercetta di gruppo verso la media globale. Questo processo viene talvolta chiamato anche “information pooling”. Rappresenta un compromesso tra l’ignorare completamente la variabile categorica (= sotto-adattamento / alto bias e bassa varianza) e dare ad ogni livello della variabile categorica “libertà completa” nell’estimazione (= sovra-adattamento / basso bias e alta varianza). È importante notare che la quantità di regolarizzazione, determinata dai parametri di varianza del modello, viene appresa dai dati. In particolare, nel modello a effetti casuali a singolo livello sopra, una (previsione) per la variabile di risposta per un campione con variabili predittive xp e variabile categorica di livello i è data da
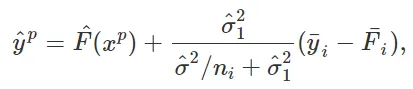
dove F(xp) è la funzione addestrata valutata in xp, σ²_1 e σ² sono stime di varianza, e yi e Fi sono medie campionarie di yij e F(xij), rispettivamente, per il livello i. Ignorare la variabile categorica darebbe la previsione yp = F(xp), e un modello completamente flessibile senza regolarizzazione darebbe yp = F(xp) + ( yi — Fi). Cioè, la differenza tra questi due casi estremi e il modello a effetti casuali è il fattore di riduzione σ²_1 / (σ²/ni + σ²_1 and σ²) (che tende a zero se il numero di campioni ni per il livello i è grande). In relazione a questo, i modelli a effetti casuali consentono una stima più efficiente (ossia con varianza inferiore) della funzione di effetti fissi F(.) [Sigrist, 2022].
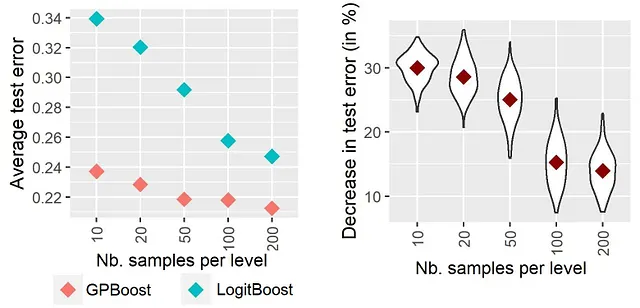
In linea con questo argomento, Sigrist [2023a, Sezione 4.1] ha scoperto in esperimenti empirici che l’incremento degli alberi combinato con gli effetti casuali (“GPBoost”) supera il classico incremento degli alberi indipendenti (“LogitBoost”) maggiormente, minore è il numero di campioni per livello di una variabile categorica, ovvero maggiore è la cardinalità di una variabile categorica. I risultati sono riprodotti sopra nella Figura 1. Questi risultati sono ottenuti simulando dati di classificazione binaria con 5000 campioni, una funzione predittiva non lineare e una variabile categorica con livelli sempre più numerosi, ovvero meno campioni per livello; vedere Sigrist [2023a] per maggiori dettagli. I risultati mostrano che la differenza nell’errore di test tra GPBoost e LogitBoost è maggiore, minore è il numero di campioni per livello della variabile categorica (= maggiore è il numero di livelli).
3 Confronto di diversi metodi utilizzando set di dati reali
Di seguito, confrontiamo diversi metodi utilizzando più set di dati reali con variabili categoriali ad alta cardinalità. Utilizziamo tutti i set di dati tabulari disponibili pubblicamente da Simchoni e Rosset [2021, 2023] e anche lo stesso ambiente sperimentale di Simchoni e Rosset [2021, 2023]. Inoltre, includiamo il set di dati Wages analizzato in Sigrist [2022].
Consideriamo i seguenti metodi:
- ‘Linear’: modelli lineari a effetti misti
- ‘NN Embed’: reti neurali profonde con embeddings
- ‘LMMNN’: combinazione di reti neurali profonde ed effetti casuali [Simchoni e Rosset, 2021, 2023]
- ‘LGBM_Num’: incremento degli alberi assegnando un numero a ogni livello delle variabili categoriali e considerandole come variabili numeriche unidimensionali
- ‘LGBM_Cat’: incremento degli alberi con l’approccio di
LightGBM[Ke et al., 2017] per variabili categoriali - ‘CatBoost’: incremento degli alberi con l’approccio di
CatBoost[Prokhorenkova et al., 2018] per variabili categoriali - ‘GPBoost’: combinazione di incremento degli alberi ed effetti casuali [Sigrist, 2022, 2023a]
Nota che, di recente (versione 1.6 e successive), la libreria XGBoost [Chen e Guestrin, 2016] ha implementato anche lo stesso approccio di LightGBM per la gestione delle variabili categoriche. Non consideriamo questo come un approccio separato qui.
Utilizziamo i seguenti set di dati:
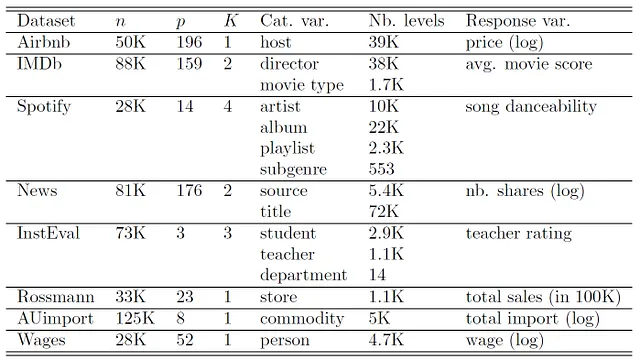
Per tutti i metodi con effetti casuali, includiamo gli effetti casuali per ogni variabile categorica menzionata nella Tabella 1 senza alcuna correlazione precedente tra gli effetti casuali. I set di dati di Rossmann, AUImport e Wages sono set di dati longitudinali. Per questi, includiamo anche pendenze casuali lineari e quadratiche; vedere (il futuro) Parte III di questa serie. Vedere Simchoni e Rosset [2021, 2023] e Sigrist [2023b] per ulteriori dettagli sui set di dati.
Eseguiamo la cross-validazione a 5 fold (CV) su ogni set di dati con l’errore quadratico medio (MSE) di test per misurare l’accuratezza della previsione. Consultare Sigrist [2023b] per informazioni dettagliate sulla configurazione sperimentale. Il codice per il pre-processing dei dati con istruzioni su come scaricare i dati e il codice per eseguire gli esperimenti può essere trovato qui. I dati pre-processati per la modellazione possono essere trovati anche sulla pagina web sopra citata per i set di dati per i quali la licenza della fonte originale lo permette.
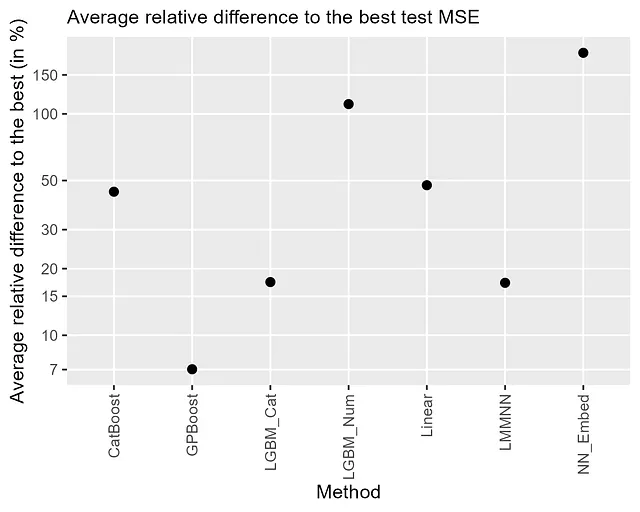
I risultati sono riassunti nella Figura 2 che mostra le differenze relative medie rispetto al MSE di test più basso. Ciò viene ottenuto calcolando prima la differenza relativa di un MSE di test di un metodo rispetto al MSE più basso per ogni set di dati, e quindi facendo la media su tutti i set di dati. I risultati dettagliati possono essere trovati in Sigrist [2023b]. Osserviamo che l’incremento combinato di alberi e effetti casuali (GPBoost) ha la maggiore accuratezza di previsione con una differenza relativa media rispetto ai migliori risultati di circa il 7%. I secondi migliori risultati sono ottenuti dall’approccio delle variabili categoriche di LightGBM (LGMB_Cat) e dalle reti neurali con effetti casuali (LMMNN), entrambi con una differenza relativa media rispetto al miglior metodo di circa il 17%. CatBoost e i modelli a effetti misti lineari hanno una performance nettamente peggiore con una differenza relativa media rispetto al miglior metodo di quasi il 50%. Dato che CatBoost “cerca di risolvere le caratteristiche categoriche” (Wikipedia al 6 luglio 2023), questo è piuttosto sconcertante. Nel complesso, le reti neurali con embedding sono le peggiori con una differenza relativa media rispetto al miglior risultato di oltre il 150%. L’incremento degli alberi con le variabili categoriche trasformate in variabili numeriche monodimensionali (LGBM_Num) ha una performance leggermente migliore con una differenza relativa media rispetto al miglior risultato di circa il 100%. Nella loro documentazione online, LightGBM raccomanda “Per una caratteristica categorica con alta cardinalità, spesso funziona meglio trattare la caratteristica come numerica” (al 6 luglio 2023). Noi arriviamo chiaramente a una conclusione diversa.
4 Conclusioni
Abbiamo confrontato empiricamente diversi metodi su dati tabulari con variabili categoriche ad alta cardinalità. I nostri risultati mostrano che, in primo luogo, i modelli di apprendimento automatico con effetti casuali hanno prestazioni migliori rispetto ai loro equivalenti senza effetti casuali e, in secondo luogo, l’incremento degli alberi con effetti casuali supera le reti neurali profonde con effetti casuali. Sebbene possano esserci diverse ragioni possibili per l’ultima scoperta, ciò è in linea con il recente lavoro di Grinsztajn et al. [2022] che ha constatato che l’incremento degli alberi supera le reti neurali profonde (e anche i random forest) su dati tabulari senza variabili categoriche ad alta cardinalità. Allo stesso modo, Shwartz-Ziv e Armon [2022] concludono che l’incremento degli alberi “supera i modelli profondi su dati tabulari”.
Nella Parte II di questa serie, mostreremo come applicare la libreria GPBoost con una demo utilizzando uno dei suddetti set di dati reali. Nella Parte III, mostreremo come i dati longitudinali, aka dati di pannello, possono essere modellati con la libreria GPBoost.
Riferimenti
- T. Chen e C. Guestrin. XGBoost: un sistema di boosting ad albero scalabile. In Atti del 22° convegno internazionale ACM SIGKDD sulla scoperta della conoscenza e l’estrazione dei dati, pagine 785-794. ACM, 2016.
- W. D. Fisher. Sulla raggruppamento per massima omogeneità. Journal of the American statistical Association, 53(284):789-798, 1958.
- L. Grinsztajn, E. Oyallon e G. Varoquaux. Perché i modelli basati su alberi continuano a essere migliori dell’apprendimento profondo sui dati tabulari tipici? In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho e A. Oh, editori, Advances in Neural Information Processing Systems, volume 35, pagine 507-520. Curran Associates, Inc., 2022.
- C. Guo e F. Berkhahn. Entity embeddings delle variabili categoriche. arXiv preprint arXiv:1604.06737, 2016.
- A. Hajjem, F. Bellavance e D. Larocque. Random forest a effetti misti per dati clusterizzati. Journal of Statistical Computation and Simulation, 84(6):1313-1328, 2014.
- G. Ke, Q. Meng, T. Finley, T. Wang, W. Chen, W. Ma, Q. Ye e T.-Y. Liu. LightGBM: un albero di decisione di boosting del gradiente altamente efficiente. In Advances in Neural Information Processing Systems, pagine 3149-3157, 2017.
- L. Prokhorenkova, G. Gusev, A. Vorobev, A. V. Dorogush e A. Gulin. CatBoost: boosting imparziale con caratteristiche categoriche. In Advances in Neural Information Processing Systems, pagine 6638-6648, 2018.
- R. Shwartz-Ziv e A. Armon. Dati tabulari: l’apprendimento profondo non è tutto ciò di cui hai bisogno. Information Fusion, 81:84-90, 2022.
- F. Sigrist. Gaussian Process Boosting. The Journal of Machine Learning Research, 23(1):10565-10610, 2022.
- F. Sigrist. Latent Gaussian Model Boosting. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(2):1894-1905, 2023a.
- F. Sigrist. Confronto tra metodi di apprendimento automatico per dati con variabili categoriche ad alta cardinalità. arXiv preprint arXiv::2307.02071 2023b.
- G. Simchoni e S. Rosset. Utilizzare effetti casuali per tener conto delle caratteristiche categoriche ad alta cardinalità e delle misure ripetute nelle reti neurali profonde. Advances in Neural Information Processing Systems, 34:25111-25122, 2021.
- G. Simchoni e S. Rosset. Integrare gli effetti casuali nelle reti neurali profonde. Journal of Machine Learning Research, 24(156):1-57, 2023.