Sblocco dell’alta precisione della classificazione differenziale privata delle immagini attraverso la scala
'Alta precisione nella classificazione differenziale privata delle immagini tramite la scala'
Un recente articolo di DeepMind sui rischi etici e sociali dei modelli di linguaggio ha identificato come un potenziale rischio il fatto che i grandi modelli di linguaggio rilascino informazioni sensibili sui dati di addestramento e che le organizzazioni che lavorano su questi modelli abbiano la responsabilità di affrontare questa situazione. Un altro recente articolo mostra che rischi simili di privacy possono anche sorgere nei modelli di classificazione standard delle immagini: è possibile trovare un’impronta digitale di ogni immagine di addestramento incorporata nei parametri del modello e parti malintenzionate potrebbero sfruttare tali impronte per ricostruire i dati di addestramento dal modello.
Tecnologie per migliorare la privacy come la privacy differenziale (DP) possono essere utilizzate durante l’addestramento per mitigare questi rischi, ma spesso comportano una significativa riduzione delle prestazioni del modello. In questo lavoro, facciamo progressi significativi verso l’addestramento ad alta precisione dei modelli di classificazione delle immagini con la privacy differenziale.
![Figura 1: (a sinistra) Illustrazione della divulgazione dei dati di addestramento in GPT-2 [credito: Carlini et al. "Estrarre dati di addestramento da grandi modelli di linguaggio", 2021]. (a destra) Esempi di addestramento CIFAR-10 ricostruiti da una rete neurale convoluzionale con 100.000 parametri [credito: Balle et al. "Ricostruire dati di addestramento con avversari informati", 2022]](https://assets-global.website-files.com/621e749a546b7592125f38ed/62ab43e65845e64d1a827c87_Figure.png)
La privacy differenziale è stata proposta come un quadro matematico per soddisfare il requisito di proteggere i record individuali durante l’analisi statistica dei dati (incluso l’addestramento dei modelli di apprendimento automatico). Gli algoritmi DP proteggono gli individui da qualsiasi inferenza sulle caratteristiche che li rendono unici (inclusa la ricostruzione completa o parziale) iniettando rumore accuratamente calibrato durante il calcolo della statistica o del modello desiderato. L’utilizzo degli algoritmi DP fornisce garanzie di privacy robuste e rigorose sia in teoria che in pratica ed è diventato uno standard de facto adottato da numerose organizzazioni pubbliche e private.
L’algoritmo DP più popolare per l’apprendimento profondo è la discesa del gradiente stocastica con privacy differenziale (DP-SGD), una modifica della SGD standard ottenuta mediante il taglio dei gradienti degli esempi individuali e l’aggiunta di sufficiente rumore per mascherare il contributo di ogni individuo a ciascun aggiornamento del modello:
- BYOL-Explore Esplorazione con Predizione Bootstrap
- Guidare un movimento per rafforzare l’apprendimento automatico in Africa
- Progettazione di meccanismi centrati sull’essere umano con intelligenza artificiale democratica
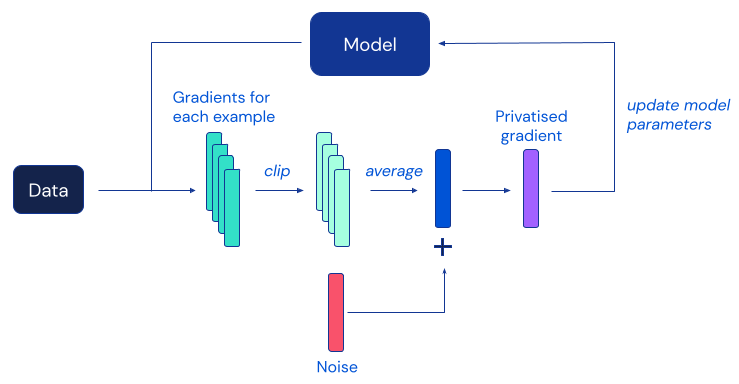
Purtroppo, lavori precedenti hanno riscontrato che, nella pratica, la protezione della privacy fornita da DP-SGD spesso comporta dei modelli significativamente meno accurati, il che rappresenta un ostacolo importante all’adozione diffusa della privacy differenziale nella comunità di apprendimento automatico. Secondo evidenze empiriche di lavori precedenti, questa degradazione dell’utilità in DP-SGD diventa più grave nei modelli di reti neurali più grandi, inclusi quelli utilizzati regolarmente per ottenere le migliori prestazioni su benchmark di classificazione delle immagini impegnativi.
Il nostro lavoro indaga questo fenomeno e propone una serie di semplici modifiche sia alla procedura di addestramento che all’architettura del modello, che portano a un significativo miglioramento dell’accuratezza dell’addestramento con DP su benchmark standard di classificazione delle immagini. La più sorprendente osservazione emersa dalla nostra ricerca è che DP-SGD può essere utilizzato per addestrare in modo efficiente modelli molto più profondi di quanto si pensasse in precedenza, purché si assicuri che i gradienti del modello siano ben comportati. Riteniamo che il notevole miglioramento delle prestazioni ottenuto dalla nostra ricerca abbia il potenziale per sbloccare applicazioni pratiche di modelli di classificazione delle immagini addestrati con garanzie formali di privacy.
La figura sottostante riassume due dei nostri principali risultati: un miglioramento di circa il 10% su CIFAR-10 rispetto al lavoro precedente quando si addestra in modo privato senza dati aggiuntivi e un’accuratezza di top-1 dell’86,7% su ImageNet quando si svolge un addestramento privato di un modello preaddestrato su un dataset diverso, avvicinandosi quasi alle migliori prestazioni non private.

Questi risultati sono ottenuti a 𝜺=8, un’impostazione standard per la calibrazione della forza della protezione offerta dalla privacy differenziale nelle applicazioni di apprendimento automatico. Ci riferiamo all’articolo per una discussione di questo parametro, così come per risultati sperimentali aggiuntivi ad altri valori di 𝜺 e anche su altri set di dati. Insieme all’articolo, stiamo anche condividendo il nostro codice di implementazione per consentire ad altri ricercatori di verificare le nostre scoperte e costruire su di esse. Speriamo che questo contributo aiuti altri interessati a rendere il training DP pratico una realtà.
Scarica la nostra implementazione JAX su GitHub.