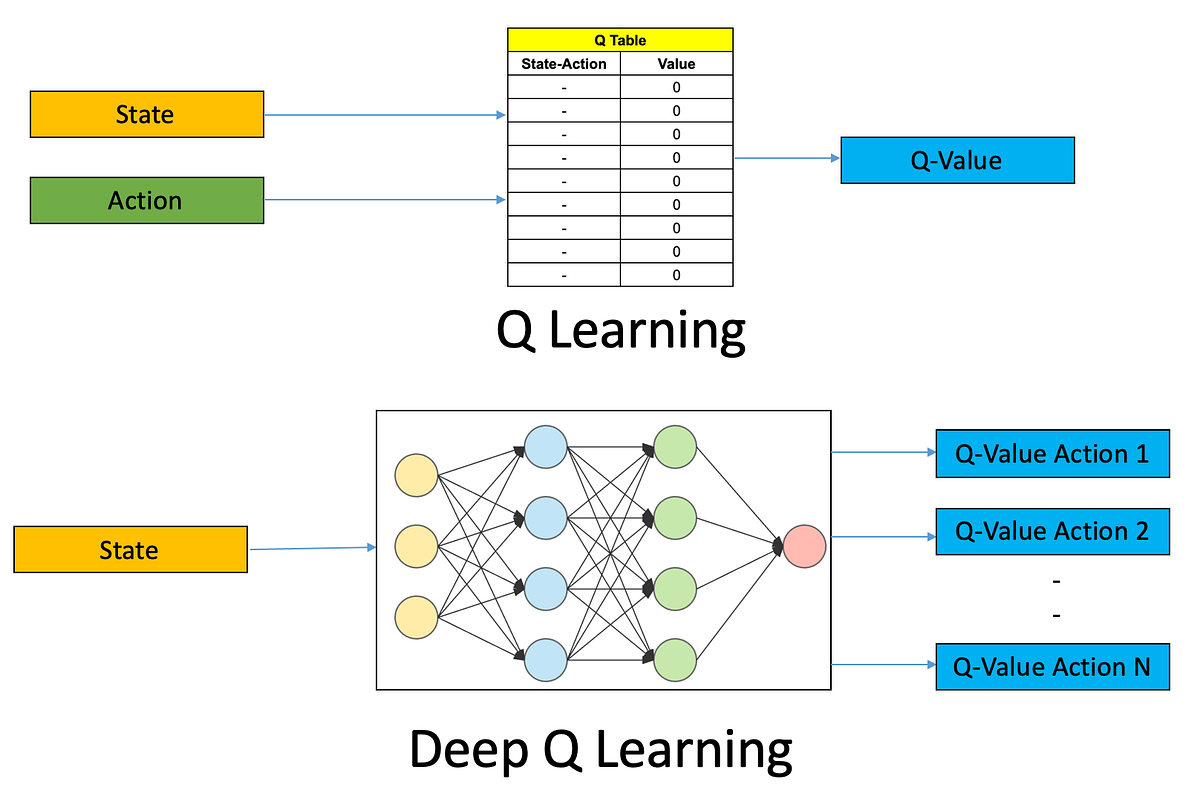
AI Grandi Modelli Linguistici e Visivi
AI Grandi Modelli Linguistici e Visivi -> AI Large Language and Vision Models
Questo articolo discute l’importanza dei grandi modelli linguistici e visivi nell’AI, le loro capacità, le potenziali sinergie, le sfide come il bias dei dati, le considerazioni etiche e il loro impatto sul mercato, evidenziando il loro potenziale per far avanzare il campo dell’intelligenza artificiale.

I modelli di grandi dimensioni, che siano modelli di linguaggio o modelli visivi, sono progettati per elaborare enormi quantità di dati utilizzando tecniche di apprendimento profondo. Questi modelli sono allenati su vasti dataset e possono imparare a riconoscere schemi e fare previsioni con una precisione incredibile. I grandi modelli di linguaggio, come GPT-3 di OpenAI e BERT di Google, sono in grado di generare testo in linguaggio naturale, rispondere alle domande, e persino tradurre tra lingue. I grandi modelli visivi, come CLIP di OpenAI e Vision Transformer di Google, possono riconoscere oggetti e scene in immagini e video con una precisione notevole. Combinando questi modelli di linguaggio e visivi, i ricercatori sperano di creare sistemi di intelligenza artificiale più avanzati che possano comprendere il mondo in modo più simile all’essere umano. Tuttavia, questi modelli sollevano anche preoccupazioni riguardo al bias dei dati, alle risorse computazionali e al potenziale abuso, e i ricercatori stanno lavorando attivamente per affrontare questi problemi. In generale, i grandi modelli sono all’avanguardia nel campo dell’IA e hanno grandi promesse per lo sviluppo di macchine più avanzate e intelligenti.
L’era digitale
Il XXI secolo è stato caratterizzato da un aumento significativo del volume, della velocità e della varietà di dati generati e raccolti. Con la diffusione delle tecnologie digitali e di Internet, i dati hanno iniziato ad essere generati su una scala e velocità senza precedenti, da una vasta gamma di fonti, tra cui i social media, i sensori e i sistemi transazionali. Ricordiamo alcuni di essi:
- Come gestire MLOps come un professionista Una guida al Machine Learning senza lacrime.
- Incontra Gorilla L’LLM arricchito da API di UC Berkeley e Microsoft supera GPT-4, Chat-GPT e Claude.
- Bootcamp LLM Full Stack gratuito
- La crescita di Internet: Internet è cresciuto rapidamente in termini di dimensioni e popolarità durante gli anni ’90, creando enormi quantità di dati che possono essere analizzati per ottenere informazioni.
- La proliferazione dei dispositivi digitali: l’uso diffuso di smartphone, tablet e altri dispositivi connessi ha creato una massa di dati dai sensori, dal tracciamento della posizione e dalle interazioni dell’utente.
- La crescita dei social media: le piattaforme di social media come Facebook e Twitter hanno creato enormi quantità di dati attraverso i contenuti generati dagli utenti, come post, commenti e like.
- L’aumento dell’e-commerce: lo shopping online e le piattaforme di e-commerce generano grandi quantità di dati sul comportamento dei consumatori, le preferenze e le transazioni.
Queste e altre tendenze hanno portato ad un aumento significativo della quantità di dati generati e raccolti e hanno creato la necessità di nuove tecnologie e approcci per gestire e analizzare questi dati. Ciò ha portato allo sviluppo di tecnologie di big data come Hadoop, Spark e database NoSQL, così come nuove tecniche per l’elaborazione e l’analisi dei dati, tra cui l’apprendimento automatico e l’apprendimento profondo. In realtà, la crescita dei big data è stato un fattore chiave per lo sviluppo delle tecniche di apprendimento profondo, poiché gli approcci tradizionali di apprendimento automatico spesso non erano in grado di analizzare ed estrarre informazioni da set di dati grandi e complessi.
Gli algoritmi di apprendimento profondo, che utilizzano reti neurali artificiali con più strati, sono stati in grado di superare queste limitazioni imparando da grandi quantità di dati e riconoscendo schemi e relazioni complesse all’interno di quei dati. Ciò ha permesso lo sviluppo di modelli potenti in grado di elaborare una vasta gamma di tipi di dati, tra cui testo, immagini e audio. Man mano che questi modelli diventavano più sofisticati e in grado di gestire set di dati più grandi e complessi, hanno dato vita ad una nuova era di intelligenza artificiale e apprendimento automatico, con applicazioni in campi come l’elaborazione del linguaggio naturale, la visione artificiale e la robotica. In generale, lo sviluppo dell’apprendimento profondo è stato una svolta importante nel campo dell’IA, e ha aperto nuove possibilità per l’analisi dei dati, l’automazione e la presa di decisioni in una vasta gamma di settori e applicazioni.
Una sinergia di Grande, Profondo, Grande
I modelli di linguaggio e visivi di grandi dimensioni, come GPT3 / GTP4 e CLIP, sono speciali perché sono in grado di elaborare e comprendere grandi quantità di dati complessi, tra cui testo, immagini e altre forme di informazione. Questi modelli utilizzano tecniche di apprendimento profondo per analizzare e imparare da enormi quantità di dati, consentendo loro di riconoscere schemi, fare previsioni e generare output di alta qualità. Uno dei principali vantaggi dei grandi modelli di linguaggio è la loro capacità di generare testo in linguaggio naturale che somiglia da vicino alla scrittura umana. Questi modelli possono produrre passaggi coerenti e convincenti su una vasta gamma di argomenti, rendendoli utili per applicazioni come la traduzione del linguaggio, la creazione di contenuti e i chatbot. Allo stesso modo, i grandi modelli visivi sono in grado di riconoscere e categorizzare immagini con una precisione notevole. Possono identificare oggetti, scene e persino emozioni rappresentate nelle immagini e possono generare descrizioni dettagliate di ciò che vedono. Le capacità uniche di questi modelli hanno molte applicazioni pratiche in campi come l’elaborazione del linguaggio naturale, la visione artificiale e l’intelligenza artificiale, e hanno il potenziale per rivoluzionare il modo in cui interagiamo con la tecnologia e elaboriamo le informazioni.
La combinazione di grandi modelli di linguaggio e visivi può fornire diverse sinergie che possono essere sfruttate in una varietà di applicazioni. Queste sinergie includono:
- Miglioramento della comprensione multimodale: i grandi modelli linguistici sono eccellenti nel trattare i dati di testo, mentre i grandi modelli visivi sono eccellenti nel trattare i dati di immagini e video. Quando questi modelli vengono combinati, possono creare una comprensione più completa del contesto in cui i dati sono presentati. Ciò può portare a previsioni più accurate e a una migliore presa di decisioni.
- Miglioramento dei sistemi di raccomandazione: combinando grandi modelli linguistici e visivi, è possibile creare sistemi di raccomandazione più precisi e personalizzati. Ad esempio, nel commercio elettronico, un modello potrebbe utilizzare il riconoscimento delle immagini per capire le preferenze di un cliente in base ai loro acquisti o visualizzazioni precedenti, e poi utilizzare l’elaborazione del linguaggio per raccomandare i prodotti più pertinenti alle preferenze del cliente.
- Miglioramento dei chatbot e degli assistenti virtuali: la combinazione di grandi modelli linguistici e visivi può migliorare l’accuratezza e la naturalezza dei chatbot e degli assistenti virtuali. Ad esempio, un assistente virtuale potrebbe utilizzare il riconoscimento delle immagini per capire il contesto della richiesta di un utente, e poi utilizzare l’elaborazione del linguaggio per fornire una risposta più accurata e pertinente.
- Miglioramento della funzionalità di ricerca: combinando grandi modelli linguistici e visivi, è possibile creare una funzionalità di ricerca più accurata e completa. Ad esempio, un motore di ricerca potrebbe utilizzare il riconoscimento delle immagini per capire il contenuto di un’immagine, e poi utilizzare l’elaborazione del linguaggio per fornire risultati di ricerca più pertinenti in base al contenuto dell’immagine.
- Miglioramento della creazione di contenuti: la combinazione di grandi modelli linguistici e visivi può anche migliorare la creazione di contenuti, come nel montaggio video o nella pubblicità. Ad esempio, uno strumento di editing video potrebbe utilizzare il riconoscimento delle immagini per identificare gli oggetti in un video, e poi utilizzare l’elaborazione del linguaggio per generare didascalie o altri sovrapposizioni di testo in base al contenuto del video.
- Formazione più efficiente: i grandi modelli linguistici e visivi possono essere addestrati separatamente e poi combinati, il che può essere più efficiente che addestrare un singolo grande modello da zero. Questo perché addestrare un grande modello da zero può essere computazionalmente intensivo e richiedere molto tempo, mentre addestrare modelli più piccoli e poi combinarli può essere più veloce ed efficiente.
In generale, la combinazione di grandi modelli linguistici e visivi può portare a un’elaborazione e analisi dei dati più accurata, efficiente e completa, e può essere sfruttata in una vasta gamma di applicazioni, dalla elaborazione del linguaggio naturale alla visione artificiale e alla robotica.
GAI o non GAI
È difficile prevedere se lo sviluppo di grandi modelli porterà alla creazione di intelligenza artificiale generale (GAI), poiché la GAI è un concetto altamente complesso e teorico che rimane oggetto di molto dibattito e speculazione nel campo dell’intelligenza artificiale. Sebbene i grandi modelli abbiano compiuto progressi significativi in aree come l’elaborazione del linguaggio naturale, il riconoscimento delle immagini e la robotica, sono ancora limitati dai loro dati di addestramento e dalla programmazione e non sono ancora in grado di una vera generalizzazione o apprendimento autonomo. Inoltre, la creazione di GAI richiederebbe progressi in diverse aree della ricerca sull’IA, tra cui l’apprendimento non supervisionato, il ragionamento e la presa di decisioni. Sebbene i grandi modelli siano un passo nella giusta direzione, sono ancora lontani dal raggiungere il livello di intelligenza e adattabilità necessario per la GAI. In breve, sebbene lo sviluppo di grandi modelli sia un passo importante verso forme più avanzate di intelligenza artificiale, non è ancora certo se porteranno alla creazione di intelligenza artificiale generale.
Sfide
Il bias dei dati è una preoccupazione significativa nei grandi modelli, poiché questi modelli vengono addestrati su enormi set di dati che possono contenere dati di bias o discriminanti. Il bias dei dati si verifica quando i dati utilizzati per addestrare un modello non rappresentano la diversità della popolazione del mondo reale, con il risultato che il modello produce output di bias o discriminatori. Ad esempio, se un grande modello linguistico è addestrato su dati di testo che sono di bias contro un particolare genere o etnia, il modello può produrre linguaggio di bias o discriminatorio quando genera testo o fa previsioni. Allo stesso modo, se un grande modello visivo è addestrato su dati di immagini che sono di bias contro alcuni gruppi, il modello può produrre output di bias o discriminatori quando esegue compiti come il riconoscimento degli oggetti o la didascalia delle immagini. Il bias dei dati può avere conseguenze gravi, poiché può perpetuare e persino amplificare le disuguaglianze sociali ed economiche esistenti. È quindi cruciale identificare e mitigare il bias dei dati nei grandi modelli, sia durante l’addestramento che durante la distribuzione.
Un modo per mitigare il bias dei dati è assicurarsi che i set di dati utilizzati per addestrare i grandi modelli siano diversi e rappresentativi della popolazione del mondo reale. Ciò può essere realizzato attraverso una cura attenta del set di dati e l’augmentazione, oltre all’uso di metriche e tecniche di equità durante l’addestramento e la valutazione del modello. Inoltre, è importante monitorare regolarmente e verificare i grandi modelli per il bias e prendere provvedimenti correttivi quando necessario. Ciò può comportare il riaddestramento del modello su dati più diversi o l’uso di tecniche di post-elaborazione per correggere gli output di bias. Nel complesso, il bias dei dati è una preoccupazione significativa nei grandi modelli, ed è cruciale adottare misure proattive per identificare e mitigare il bias al fine di garantire che questi modelli siano equi e giusti.
Lato Etico
La decisione di OpenAI di concedere esclusivi diritti commerciali a Microsoft per il suo grande modello linguistico GPT-3 ha generato un dibattito all’interno della comunità dell’AI. Da un lato, si potrebbe sostenere che collaborare con una grande azienda tecnologica come Microsoft possa fornire le risorse e i finanziamenti necessari per far avanzare ulteriormente la ricerca e lo sviluppo dell’AI. Inoltre, Microsoft si è impegnata a utilizzare GPT-3 in modo responsabile ed etico e ha promesso di investire nello sviluppo di AI che sia allineata con la missione di OpenAI. D’altra parte, alcuni hanno sollevato preoccupazioni riguardo la potenziale monopolizzazione dell’accesso a GPT-3 e ad altre tecnologie avanzate di AI da parte di Microsoft, che potrebbe limitare l’innovazione e creare squilibri di potere nell’industria tecnologica. Inoltre, alcuni hanno sostenuto che la decisione di OpenAI di concedere esclusivi diritti commerciali a Microsoft vada contro la sua dichiarata missione di far avanzare l’AI in modo sicuro e vantaggioso per la società, poiché potrebbe privilegiare gli interessi commerciali rispetto ai benefici per la comunità. In ultima analisi, se la decisione di OpenAI di concedere esclusivi diritti commerciali a Microsoft sia “accettabile” o meno dipende dalla prospettiva e dai valori di ognuno. Sebbene ci siano preoccupazioni valide riguardo ai potenziali rischi e svantaggi di tale partnership, ci sono anche potenziali benefici e opportunità che potrebbero derivare dalla collaborazione con una grande azienda tecnologica come Microsoft. È compito della comunità dell’AI e della società nel suo complesso monitorare attentamente l’impatto di questa partnership e garantire che l’AI sia sviluppata e implementata in modo sicuro, vantaggioso ed equo per tutti.
Quote di Mercato
Ciascuno di questi modelli ha i propri punti di forza e di debolezza e possono essere utilizzati per una varietà di compiti di elaborazione del linguaggio naturale, come la traduzione del linguaggio, la generazione di testo, la risposta a domande e altro ancora. Come modello linguistico di AI, ChatGPT è considerato uno dei modelli linguistici più avanzati ed efficaci attualmente disponibili. Tuttavia, esistono altri modelli che possono superare ChatGPT su determinati compiti, a seconda delle specifiche metriche utilizzate per valutare le prestazioni. Ad esempio, alcuni modelli hanno ottenuto punteggi più elevati su benchmark di elaborazione del linguaggio naturale come GLUE (General Language Understanding Evaluation) o SuperGLUE, che valutano la capacità di un modello di comprendere e ragionare sul testo in linguaggio naturale. Tra questi modelli ci sono:
- GShard-GPT3, un modello linguistico su larga scala sviluppato da Google che ha raggiunto prestazioni all’avanguardia su diversi benchmark di NLP
- T5 (Text-to-Text Transfer Transformer), anch’esso sviluppato da Google, che ha raggiunto prestazioni elevate su una vasta gamma di compiti di NLP
- GPT-Neo, un progetto guidato dalla comunità che mira a sviluppare modelli linguistici su larga scala simili a GPT-3, ma che sono più accessibili e possono essere formati su un’ampia gamma di hardware
Tuttavia, vale la pena notare che le prestazioni su questi benchmark sono solo uno degli aspetti delle capacità complessive di un modello linguistico e che ChatGPT e altri modelli possono superare questi modelli in altri compiti o in applicazioni del mondo reale. Inoltre, il campo dell’AI è in costante evoluzione e vengono sviluppati continuamente nuovi modelli che potrebbero spingere i limiti di ciò che è possibile.
Link Utili
- Cosa sta facendo ChatGPT… e perché funziona?
- GPT-3 di OpenAI: https://openai.com/blog/gpt-3-unleashed/
- BERT di Google: https://ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html
- RoBERTa di Facebook: https://ai.facebook.com/blog/roberta-an-optimized-method-for-pretraining-self-supervised-nlp-systems/
- T5 di Google: https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html
- CLIP (Contrastive Language-Image Pre-Training) di OpenAI: https://openai.com/blog/clip/
- Turing-NLG di Microsoft: https://www.microsoft.com/en-us/research/blog/microsoft-announces-turing-nlg-state-of-the-art-model-for-natural-language-generation/
- Libreria Transformer di Hugging Face: https://huggingface.co/transformers/
Ihar Rubanau è Senior Data Scientist presso Sigma Software Group