AI incontra PowerPoint
AI e PowerPoint
Automazione delle presentazioni di ricerca aziendale con Streamlit, LangChain e Yahoo Finance
Questo articolo è stato originariamente pubblicato sul blog di Streamlit il 2 agosto 2023.
Introduzione
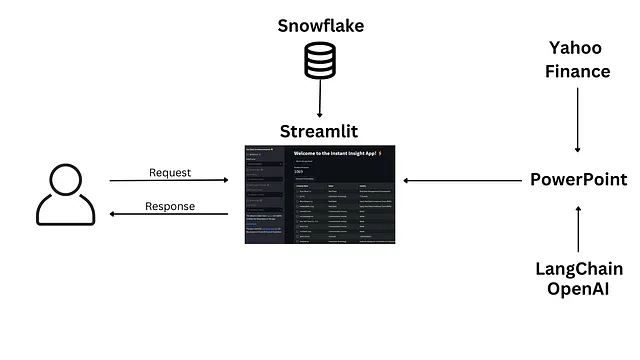
In questo articolo ti guideremo attraverso il funzionamento del backend dell’app Instant Insight, un progetto open-source che ha vinto il terzo posto nello Streamlit Hackathon per il Summit di Snowflake nel maggio 2023. L’app web è progettata per generare presentazioni PowerPoint con ricerche aziendali e di valore utilizzando dati da Yahoo Finance e ChatGPT.
Per contestualizzare, immaginiamo di lavorare nel settore delle vendite per un’azienda B2B SaaS con centinaia di potenziali clienti e offrire i seguenti prodotti: software di contabilità e pianificazione, CRM, chatbot e archiviazione cloud dei dati. Il tuo compito è condurre ricerche sui potenziali clienti, incluse analisi finanziarie e SWOT, esplorare il panorama della concorrenza, creare proposte di valore e condividere una presentazione con il tuo team. I dati dei potenziali clienti sono memorizzati in un database Snowflake, che alimenta il tuo sistema CRM. Puoi utilizzare l’app Instant Insight per filtrare rapidamente i potenziali clienti in base a vari parametri. Successivamente, seleziona il potenziale cliente che desideri includere nella presentazione e fai clic sul pulsante per generare la presentazione. In un minuto, la presentazione PowerPoint contenente tutte le ricerche sarà pronta per il download.
L’architettura ad alto livello dell’app è la seguente:
- Langchain 101 Estrarre dati strutturati (JSON)
- Quali modelli di Deep Learning utilizzare con le scansioni MRI e CT in 3D?
- VoAGI News, 9 agosto Dimenticate ChatGPT, questo nuovo assistente AI è avanti anni luce • 7 passaggi per padroneggiare le tecniche di pulizia e preprocessamento dei dati
Indice
- Collegare l’app Streamlit a Snowflake
- Creare un’interfaccia utente con filtri dinamici e una tabella interattiva
- Recuperare dati aziendali da Yahoo Finance
- Creare grafici utilizzando Plotly
- Utilizzare l’API Clearbit per ottenere i loghi delle aziende
- Utilizzare LangChain e GPT 3.5 LLM per scrivere analisi SWOT e proposta di valore
- Estrarre dati strutturati dalla risposta GPT
- Generare diapositive utilizzando python-pptx
Collegare l’app Streamlit a Snowflake
Prima di tutto, ottenere alcuni dati. Per farlo, utilizzare il connettore Snowflake:
import snowflake.connector# ottenere le credenziali Snowflake dai segreti di StreamlitSNOWFLAKE_ACCOUNT = st.secrets["snowflake_credentials"]["SNOWFLAKE_ACCOUNT"]SNOWFLAKE_USER = st.secrets["snowflake_credentials"]["SNOWFLAKE_USER"]SNOWFLAKE_PASSWORD = st.secrets["snowflake_credentials"]["SNOWFLAKE_PASSWORD"]SNOWFLAKE_DATABASE = st.secrets["snowflake_credentials"]["SNOWFLAKE_DATABASE"]SNOWFLAKE_SCHEMA = st.secrets["snowflake_credentials"]["SNOWFLAKE_SCHEMA"]@st.cache_resourcedef get_database_session(): """Restituisce un oggetto sessione di database.""" return snowflake.connector.connect( account=SNOWFLAKE_ACCOUNT, user=SNOWFLAKE_USER, password=SNOWFLAKE_PASSWORD, database=SNOWFLAKE_DATABASE, schema=SNOWFLAKE_SCHEMA, )@st.cache_datadef get_data(): """Restituisce un DataFrame pandas con i dati da Snowflake.""" query = 'SELECT * FROM us_prospects;' cur = conn.cursor() cur.execute(query) # Recupera il risultato come DataFrame pandas column_names = [col[0] for col in cur.description] data = cur.fetchall() df = pd.DataFrame(data, columns=column_names) # Chiudi la connessione a Snowflake cur.close() conn.close() return df# ottenere i dati da Snowflakeconn = get_database_session()df = get_data(conn)I dati sensibili come l’account Snowflake, il nome utente, la password, il nome del database e lo schema vengono archiviati nei segreti e recuperati chiamando st.secrets (leggi di più qui).
Successivamente, definire due funzioni:
get_database_session() inizializza un oggetto di connessioneget_data() esegue una query SQL e restituisce un DataFrame pandasUtilizza una semplice query SELECT * per recuperare tutti i dati dalla tabella us_prospects.
Crea un’interfaccia utente con filtri dinamici e una tabella interattiva
Ora utilizziamo un po’ di magia di Streamlit per sviluppare un front-end per l’applicazione. Crea un pannello laterale che contiene quattro filtri multi-select dinamici e aggiungi una casella di controllo che consente agli utenti di selezionare tutti i valori.
I filtri nella tua app funzionano in sequenza. Si prevede che gli utenti li applichino individualmente, dall’alto verso il basso. Una volta applicato il primo filtro, il secondo filtro diventa disponibile e contiene solo etichette pertinenti. Dopo l’applicazione di ogni filtro, il DataFrame sottostante viene pre-filtrato e la variabile num_of_pros viene aggiornata per riflettere il numero di prospetti selezionati.
Vedi i filtri in azione:
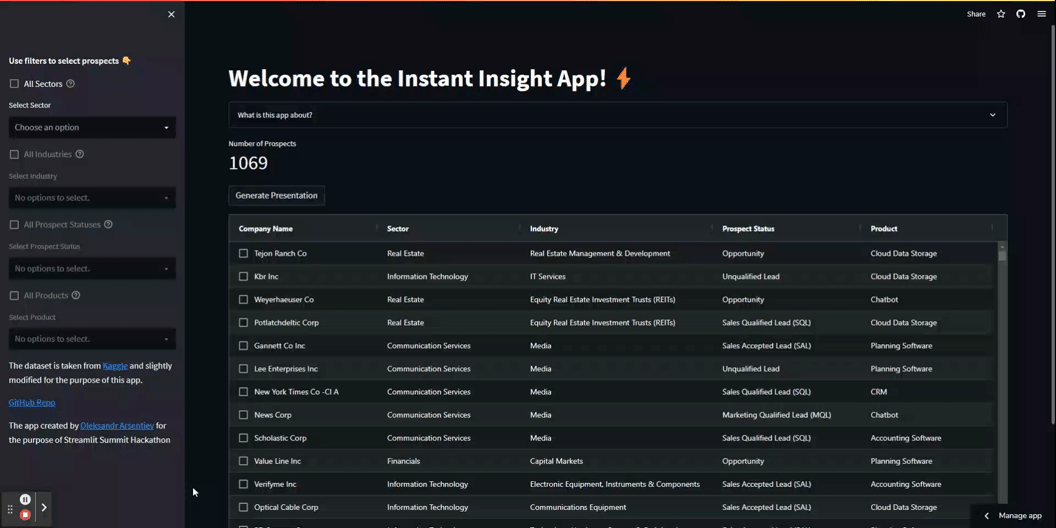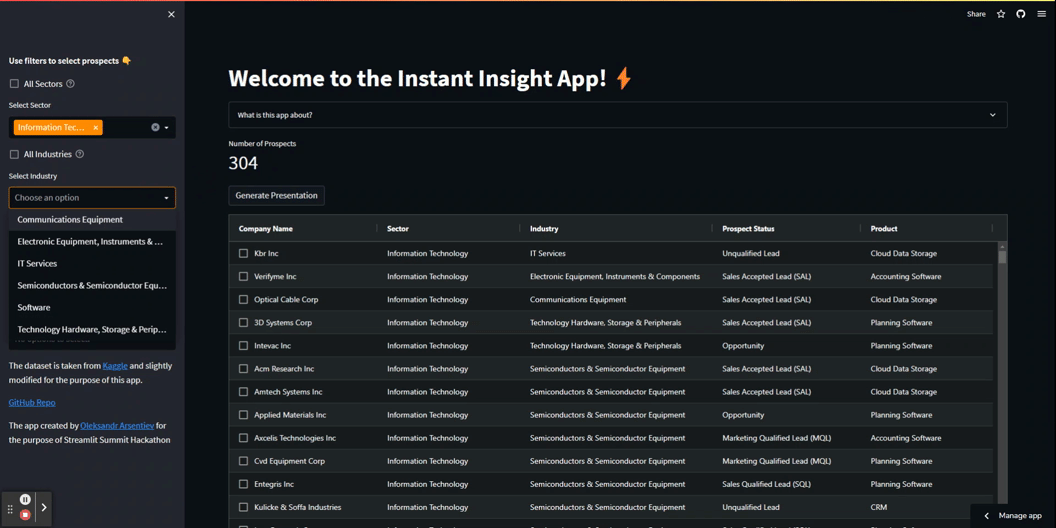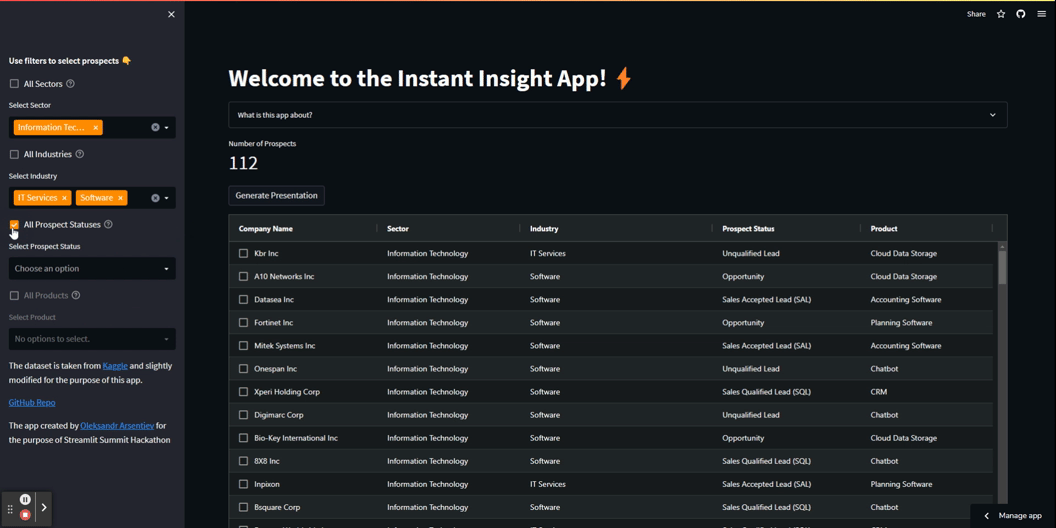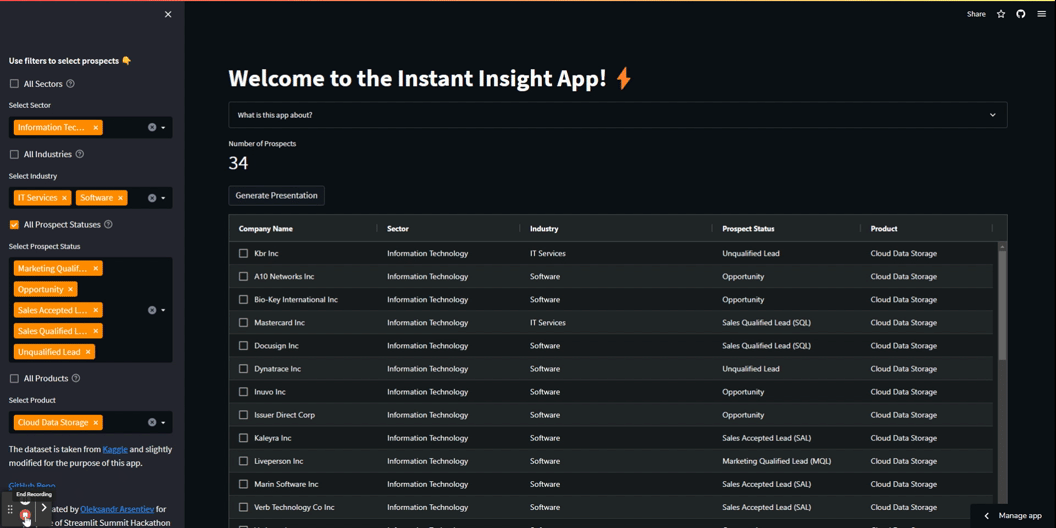
Ecco il codice per creare i primi due filtri:
# crea i filtri laterali st.sidebar.write('**Utilizza i filtri per selezionare i prospetti** 👇')sector_checkbox = st.sidebar.checkbox('Tutti i Settori', help='Seleziona questa casella per selezionare tutti i settori')unique_sector = sorted(df['SETORE'].unique())# se la casella di selezione di tutti è selezionata allora seleziona tutti i settoriif sector_checkbox: selected_sector = st.sidebar.multiselect('Seleziona Settore', unique_sector, unique_sector)else: selected_sector = st.sidebar.multiselect('Seleziona Settore', unique_sector)# se un utente ha selezionato un settore allora consenti di selezionare la casella di controllo di tutte le industrieif len(selected_sector) > 0: industry_checkbox = st.sidebar.checkbox('Tutte le Industrie', help='Seleziona questa casella per selezionare tutte le industrie') # filtraggio dei dati df = df[(df['SETORE'].isin(selected_sector))] # mostra il numero di prospetti selezionati num_of_pros = str(df.shape[0])else: industry_checkbox = st.sidebar.checkbox('Tutte le Industrie', help='Seleziona questa casella per selezionare tutte le industrie', disabled=True) # mostra il numero di prospetti selezionati num_of_pros = str(df.shape[0])# se la casella di selezione di tutti è selezionata allora seleziona tutte le industrieunique_industry = sorted(df['INDUSTRIA'].loc[df['SETORE'].isin(selected_sector)].unique())if industry_checkbox: selected_industry = st.sidebar.multiselect('Seleziona Industria', unique_industry, unique_industry)else: selected_industry = st.sidebar.multiselect('Seleziona Industria', unique_industry)# se un utente ha selezionato un'industria allora consenti di selezionare la casella di controllo di tutti gli stati dei prospettif len(selected_industry) > 0: status_checkbox = st.sidebar.checkbox('Tutti gli Stati dei Prospetti', help='Seleziona questa casella per selezionare tutti gli stati dei prospetti') # filtraggio dei dati df = df[(df['SETORE'].isin(selected_sector)) & (df['INDUSTRIA'].isin(selected_industry))] # mostra il numero di prospetti selezionati num_of_pros = str(df.shape[0])else: status_checkbox = st.sidebar.checkbox('Tutti gli Stati dei Prospetti', help='Seleziona questa casella per selezionare tutti gli stati dei prospetti', disabled=True)Successivamente, utilizza AgGrid per creare una tabella interattiva che visualizza i dati, consentendo agli utenti di selezionare i prospetti di generazione di diapositive (leggi di più qui).
Piazza una casella di controllo su ogni riga della tabella, consentendo agli utenti di selezionare solo una riga. Inoltre, imposta larghezza personalizzata delle colonne e altezza della tabella.
Ecco come apparirà:
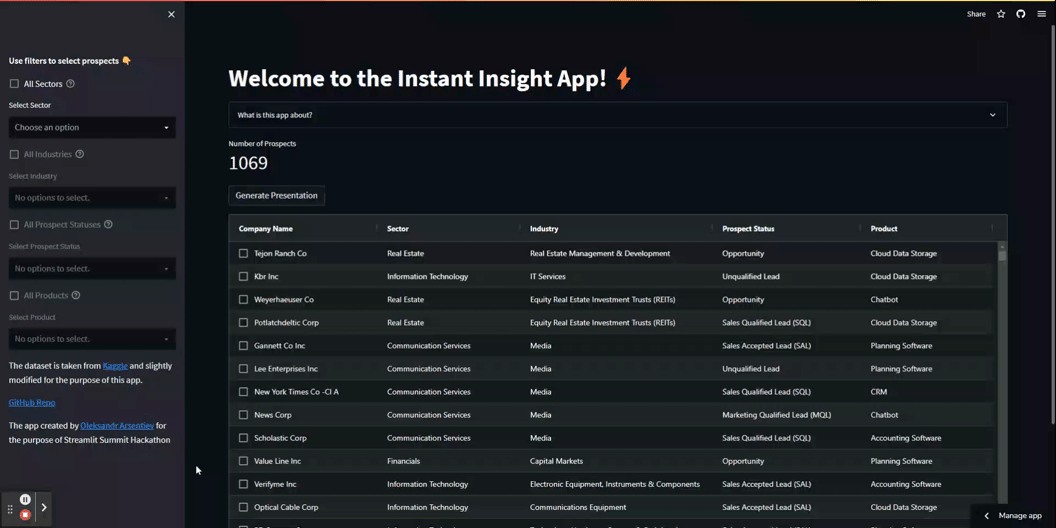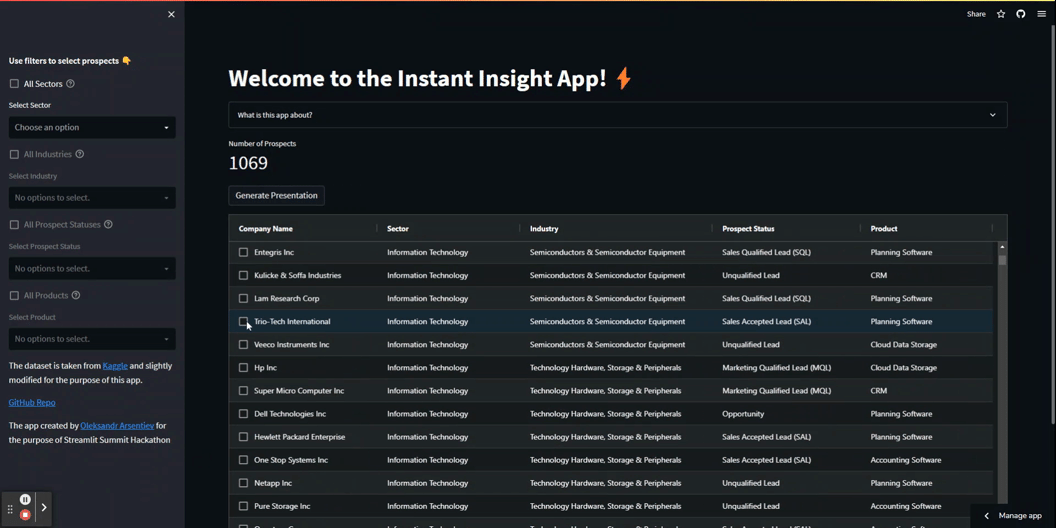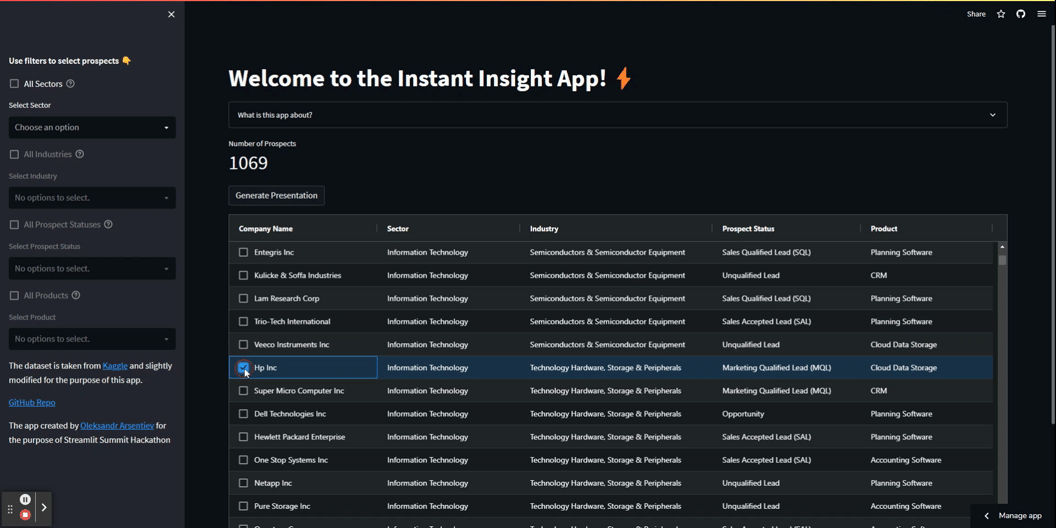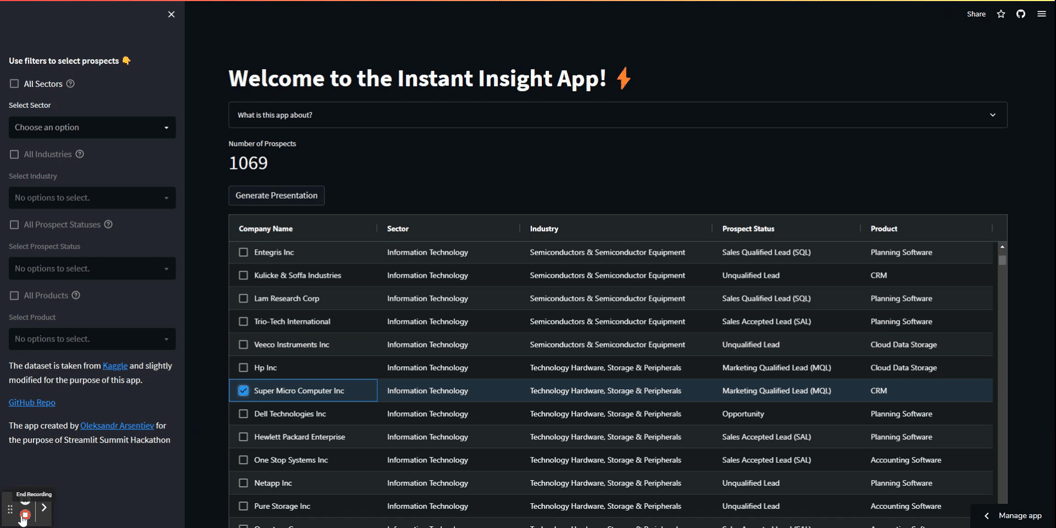
Ecco il codice per creare questa tabella:
from st_aggrid import AgGridfrom st_aggrid.grid_options_builder import GridOptionsBuilderfrom st_aggrid import GridUpdateMode, DataReturnModeimport pandas as pd# creazione della tabella dinamica AgGrid e configurazione dei parametrigb = GridOptionsBuilder.from_dataframe(df)gb.configure_selection(selection_mode="single", use_checkbox=True)gb.configure_column(field='Nome Azienda', width=270)gb.configure_column(field='Settore', width=260)gb.configure_column(field='Industria', width=350)gb.configure_column(field='Stato Prospetto', width=270)gb.configure_column(field='Prodotto', width=240)gridOptions = gb.build()response = AgGrid( df, gridOptions=gridOptions, height=600, update_mode=GridUpdateMode.SELECTION_CHANGED, data_return_mode=DataReturnMode.FILTERED_AND_SORTED, fit_columns_on_grid_load=False, theme='alpine', allow_unsafe_jscode=True)# ottenere le righe selezionateresponse_df = pd.DataFrame(response["selected_rows"])Recupera dati aziendali da Yahoo Finance
Supponiamo che l’utente abbia selezionato un’azienda per la ricerca e tu devi raccogliere alcuni dati su di essa. La tua fonte di dati principale è Yahoo Finance, a cui accederai tramite la libreria yahooquery – un’interfaccia Python per i punti di accesso non ufficiali dell’API di Yahoo Finance. Consente agli utenti di recuperare quasi tutti i dati visibili tramite l’interfaccia di Yahoo Finance.
Ecco la slide di panoramica con i dati di Yahoo Finance:

Utilizza la classe Ticker di yahooquery per ottenere dati quantitativi e qualitativi su un’azienda selezionata. Passa semplicemente il simbolo dell’azienda come argomento, chiama la proprietà richiesta e recupera i dati dal dizionario restituito.
Ecco il codice che recupera i dati per la panoramica aziendale:
from yahooquery import Tickerselected_ticker = 'ABC'ticker = Ticker(selected_ticker)# ottieni informazioni sull'aziendanome = ticker.price[selected_ticker]['shortName']settore = ticker.summary_profile[selected_ticker]['sector']settore_industriale = ticker.summary_profile[selected_ticker]['industry']dipendenti = ticker.summary_profile[selected_ticker]['fullTimeEmployees']paese = ticker.summary_profile[selected_ticker]['country']città = ticker.summary_profile[selected_ticker]['city']sito_web = ticker.summary_profile[selected_ticker]['website']riassunto = ticker.summary_profile[selected_ticker]['longBusinessSummary']L’app utilizza i dati di Yahoo Finance per creare grafici che illustrano le prestazioni finanziarie nel tempo. Una slide mostra metriche finanziarie di base come il prezzo delle azioni, il debito totale, il fatturato totale e l’EBITDA nel tempo.
Parlerò di tracciamento più avanti. Per ora, concentriamoci sul recupero dei dati finanziari da Yahoo Finance. Le funzioni get_stock() e get_financials() restituiscono dataframe con le metriche finanziarie rilevanti. I dati sul prezzo delle azioni sono memorizzati separatamente dalle altre metriche finanziarie, per questo motivo vengono chiamate due proprietà:
ticker.history() per recuperare dati storici sul prezzo di uno o più simboli (leggi la documentazione qui)ticker.all_financial_data() per recuperare tutti i dati finanziari, inclusi il conto economico, il bilancio, il flusso di cassa e le misure di valutazione (leggi la documentazione qui)
Ecco il codice utilizzato per generare quattro dataframe con dati storici sul prezzo delle azioni, il fatturato, il debito totale e l’EBITDA:
from yahooquery import Tickerimport pandas as pddef get_stock(ticker, period, interval): """funzione per ottenere dati sulle azioni da Yahoo Finance. Prende come argomenti il simbolo azionario, il periodo e l'intervallo e restituisce un DataFrame""" hist_df = ticker.history(period=period, interval=interval) hist_df = hist_df.reset_index() # converti in maiuscolo i nomi delle colonne hist_df.columns = [x.capitalize() for x in hist_df.columns] return hist_dfdef get_financials(df, col_name, metric_name): """funzione per ottenere metriche finanziarie da un DataFrame. Prende come argomenti il DataFrame, il nome della colonna e il nome della metrica e restituisce un DataFrame""" metrica = df.loc[:, ['asOfDate', col_name]] metric_df = pd.DataFrame(metrica).reset_index() metric_df.columns = ['Simbolo', 'Anno', metric_name] return metric_dfselected_ticker = 'ABC'ticker = Ticker(selected_ticker)# ottieni tutti i dati finanziarifin_df = ticker.all_financial_data()# crea dataframe per ciascuna metricastock_df = get_stock(ticker=ticker, period='5y', interval='1mo')rev_df = get_financials(df=fin_df, col_name='TotalRevenue', metric_name='Fatturato totale')debt_df = get_financials(df=fin_df, col_name='TotalDebt', metric_name='Debito totale')ebitda_df = get_financials(df=fin_df, col_name='NormalizedEBITDA', metric_name='EBITDA')I dati di Yahoo Finance vengono anche utilizzati in un’altra slide per l’analisi dei concorrenti, in cui le prestazioni di un’azienda vengono confrontate con quelle dei suoi concorrenti. Per realizzarla, utilizza due metriche: il fatturato totale e la percentuale di SG&A sul fatturato. Queste sono disponibili nel conto economico, quindi utilizza la proprietà ticker.income_statement() che restituisce un DataFrame (leggi di più qui).
La funzione extract_comp_financials() recupera il fatturato totale e le spese generali e amministrative (SG&A) dal DataFrame del conto economico, e mantiene solo i dati del 2022. Poiché la metrica SG&A come percentuale del fatturato non è disponibile direttamente, calcolala manualmente dividendo SG&A per il fatturato e moltiplicando per 100.
La funzione opera su un dizionario nidificato con i nomi delle aziende come chiavi e un dizionario con i ticker come valori, quindi aggiunge nuovi valori al dizionario esistente:
from yahooquery import Ticker
import pandas as pd
def estrai_ind_finanziari(tkr, nome_azienda, dict_aziende):
"""Funzione per estrarre metriche finanziarie per i concorrenti. Prende un ticker, il nome dell'azienda e un dizionario nidificato con i concorrenti come argomenti e aggiunge metriche finanziarie al dizionario"""
ticker = Ticker(tkr)
income_df = ticker.income_statement(frequency='a', trailing=False)
subset = income_df.loc[:, ['asOfDate', 'TotalRevenue', 'SellingGeneralAndAdministration']].reset_index()
# mantieni solo i dati del 2022
subset = subset[subset['asOfDate'].dt.year == 2022].sort_values(by='asOfDate', ascending=False).head(1)
# ottieni i valori
total_revenue = subset['TotalRevenue'].values[0]
sg_and_a = subset['SellingGeneralAndAdministration'].values[0]
# calcola sg&a come percentuale del totale delle entrate
sg_and_a_pct = round(sg_and_a / total_revenue * 100, 2)
# aggiungi i valori al dizionario
dict_aziende[nome_azienda]['Totale Entrate'] = total_revenue
dict_aziende[nome_azienda]['SG&A % Del Totale Entrate'] = sg_and_a_pct
# dizionario di esempio
dict_aziende_nidificato = {'Azienda 1': {'Ticker': 'ABC'}, 'Azienda 2': {'Ticker': 'XYZ'}}
# estrai dati finanziari per ogni concorrente
for chiave, valore in dict_aziende_nidificato.items():
try:
estrai_ind_finanziari(tkr=valore['Ticker'], nome_azienda=chiave, dict_aziende=dict_aziende_nidificato)
# se il ticker non viene trovato in Yahoo Finance, rimuovilo dal dizionario dei concorrenti e continua
except:
del dict_aziende_nidificato[chiave]
continueDopo aver eseguito il codice sopra, ottieni un dizionario nidificato che assomiglia alla seguente struttura:
# dizionario di output di esempio
{'Azienda 1': {'Ticker': 'ABC', 'Totale Entrate': '1234', 'SG&A % Del Totale Entrate': '10'}, 'Azienda 2': {'Ticker': 'XYZ', 'Totale Entrate': '5678', 'SG&A % Del Totale Entrate': '20'}}Successivamente, converti il dizionario nidificato in un DataFrame per passarlo a una funzione di plotting:
# crea un dataframe con i dati finanziari dei concorrenti
df_concorrenti = pd.DataFrame.from_dict(dict_aziende_nidificato, orient='index')
df_concorrenti = df_concorrenti.reset_index().rename(columns={'index': 'Nome Azienda'})Il DataFrame risultante dovrebbe assomigliare a qualcosa del genere:
Nome Azienda Ticker Totale Entrate SG&A % Del Totale Entrate
0 Azienda 1 ABC 1234 10
1 Azienda 2 XYZ 5678 20Crea grafici utilizzando Plotly
Hai filtrato i dati finanziari, ora è il momento di plottarli! Utilizza Plotly Express per creare grafici semplici ma visivamente accattivanti (leggi di più qui).
Nella sezione precedente, hai creato un DataFrame e una variabile per il nome dell’azienda. Utilizzali nella funzione plot_graph() per prendere il dataframe, i nomi delle colonne per gli assi x e y, e il titolo del grafico come argomenti:
import plotly.express as px
def plot_graph(df, x, y, title, name):
"""Funzione per plottare un grafico a linee. Prende DataFrame, assi x e y, titolo e nome come argomenti e restituisce una figura Plotly"""
fig = px.line(df, x=x, y=y, template='simple_white',
title='<b>{} {}</b>'.format(name, title))
fig.update_traces(line_color='#A27D4F')
fig.update_layout(paper_bgcolor='rgba(0,0,0,0)', plot_bgcolor='rgba(0,0,0,0)')
return fig
stock_fig = plot_graph(df=df_azioni, x='Data', y='Apertura', title='Prezzo Azioni USD', name=nome)
rev_fig = plot_graph(df=df_entrate, x='Anno', y='Totale Entrate', title='Totale Entrate USD', name=nome)
debt_fig = plot_graph(df=df_debito, x='Anno', y='Debito Totale', title='Debito Totale USD', name=nome)
ebitda_fig = plot_graph(df=df_ebitda, x='Anno', y='EBITDA', title='EBITDA USD', name=nome)Il grafico risultante dovrebbe avere un aspetto simile a questo:
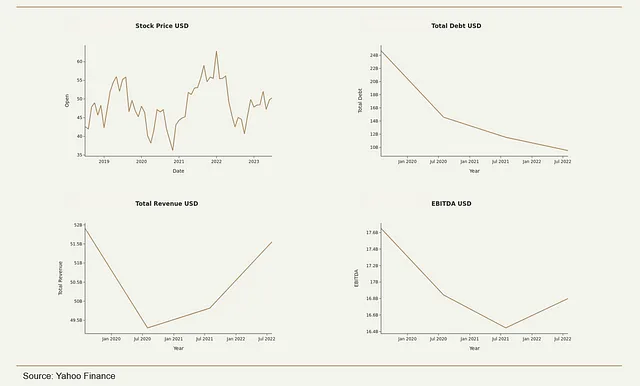
L’applicazione genera anche una diapositiva contenente un’analisi dei concorrenti per una determinata azienda. Per farlo, utilizzare la funzione peers_plot() insieme a peers_df. Questa funzione genera un grafico a barre orizzontale che confronta il fatturato totale e la percentuale di SG&A sul fatturato tra i concorrenti.
Ecco il codice:
import plotly.express as pximport pandas as pddef peers_plot(df, name, metric): """Funzione per tracciare un grafico a barre con i concorrenti. Prende come argomenti DataFrame, nome, metrica e simbolo e restituisce una figura di Plotly""" # eliminare le righe con metriche mancanti df.dropna(subset=[metric], inplace=True) df_sorted = df.sort_values(metric, ascending=False) # iterare sulle etichette e aggiungere i colori al dizionario di mappatura dei colori, evidenziare l'azienda selezionata color_map = {} for label in df_sorted['Company Name']: if label == name: color_map[label] = '#A27D4F' else: color_map[label] = '#D9D9D9' fig = px.bar(df_sorted, y='Company Name', x=metric, template='simple_white', color='Company Name', color_discrete_map=color_map, orientation='h', title='<b>{} {} vs Peers FY22</b>'.format(name, metric)) fig.update_layout(paper_bgcolor='rgba(0,0,0,0)', plot_bgcolor='rgba(0,0,0,0)', showlegend=False, yaxis_title='') return fig# tracciare i grafici dei concorrentirev_peers_fig = peers_plot(df=peers_df, name=name, metric='Total Revenue')sg_and_a_peers_fig = peers_plot(df=peers_df, name=name, metric='SG&A % Of Revenue')L’utilizzo di colori personalizzati rende la tua azienda più evidente.
I grafici a barre dovrebbero avere un aspetto simile a questo:
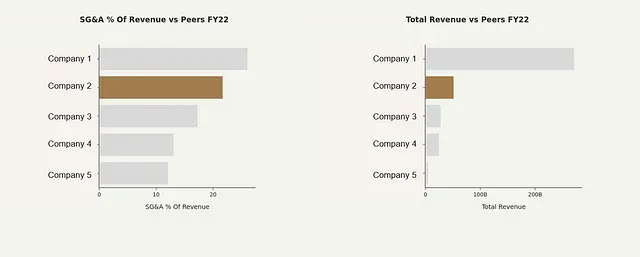
Utilizzare Clearbit API per ottenere i loghi delle aziende
Come hai visto nella diapositiva di panoramica dell’azienda, c’era il logo dell’azienda ricercata. Gli URL dei loghi non sono disponibili su Yahoo Finance, quindi utilizzare Clearbit al suo posto. Collega semplicemente il sito web dell’azienda a “https://logo.clearbit.com/” con poche righe di codice:
from yahooquery import Tickerselected_ticker = 'ABC'ticker = Ticker(selected_ticker)# ottenere il sito web dell'azienda selezionatowebsite = ticker.summary_profile[selected_ticker]['website']# ottenere l'URL del logo dell'azienda selezionatalogo_url = '<https://logo.clearbit.com/>' + websiteOra che hai l’URL del logo, verifica se funziona. Se funziona, regola le dimensioni e posizionalo su una diapositiva. Per farlo, utilizza la funzione personalizzata resize_image(), che inserisce un’immagine di logo all’interno di un contenitore e ne regola le dimensioni mantenendo il rapporto di aspetto. Ciò garantisce che tutti i loghi abbiano la stessa apparenza nonostante eventuali differenze iniziali di dimensione.
Quindi salva l’oggetto immagine localmente come “logo.png” e recuperalo per posizionarlo su una diapositiva come immagine. È possibile posizionare le figure di Plotly sulle diapositive in modo simile. Utilizza la libreria python-pptx per manipolare le diapositive e le forme di PowerPoint in modo programmato (leggi di più qui).
Ecco il processo:
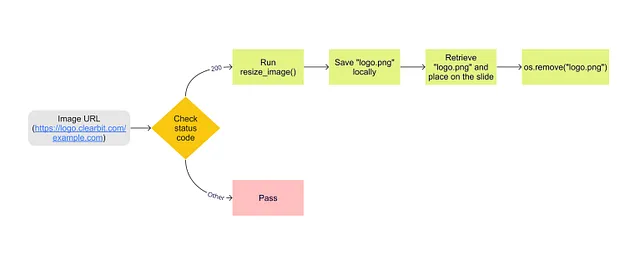
Il codice seguente utilizza la variabile logo_url (definita nello snippet di codice precedente):
from PIL import Imageimport requestsfrom pptx import Presentationfrom pptx.util import Inchesimport osdef resize_image(url): """funzione per ridimensionare i loghi mantenendo il rapporto di aspetto. Accetta l'URL come argomento e restituisce l'oggetto immagine""" # aprire l'immagine dall'URL image = Image.open(requests.get(url, stream=True).raw) # se un logo è troppo alto o troppo largo, rendere il contenitore dello sfondo due volte più grande if image.height > 140: container_width = 220 * 2 container_height = 140 * 2 elif image.width > 220: container_width = 220 * 2 container_height = 140 * 2 else: container_width = 220 container_height = 140 # creare una nuova immagine con lo stesso rapporto di aspetto dell'immagine originale new_image = Image.new('RGBA', (container_width, container_height)) # calcolare la posizione in cui incollare l'immagine in modo che sia centrata x = (container_width - image.width) // 2 y = (container_height - image.height) // 2 # incollare l'immagine nella nuova immagine new_image.paste(image, (x, y)) return new_image# creare un oggetto di presentazioneprs = Presentation('template.pptx')# selezionare la seconda diapositivaslide = prs.slides[1]# controlla se un URL del logo restituisce il codice 200 (link funzionante)if requests.get(logo_url).status_code == 200: # creare un oggetto immagine di logo logo = resize_image(logo_url) logo.save('logo.png') logo_im = 'logo.png' # aggiungi il logo alla diapositiva slide.shapes.add_picture(logo_im, left=Inches(1.2), top=Inches(0.5), width=Inches(2)) os.remove('logo.png')Eseguendo il codice sopra dovrebbe essere posizionato un logo nella diapositiva:
Utilizzare LangChain e GPT 3.5 LLM per scrivere un’analisi SWOT e una proposta di valore.
È ora di utilizzare l’IA per la ricerca aziendale!
Utilizzerai LangChain, un framework popolare progettato per semplificare la creazione di applicazioni utilizzando ChatOpenAI e Human/System Message LLMs (leggi di più qui).
La funzione generate_gpt_response() richiede due argomenti:
- gpt_input, un prompt che passerai al modello
- max_tokens, che limita il numero di token nella risposta del modello
Utilizzerai il modello gpt-3.5-turbo-0613 negli argomenti di ChatOpenAI e recupererai la chiave API di OpenAI memorizzata in Streamlit secrets. Imposterai anche la temperatura a 0 per ottenere risposte più deterministiche (leggi di più qui).
Per migliorare la qualità delle risposte di GPT, passa il seguente testo all’argomento SystemMessage: “Sei un esperto disponibile in finanza, mercato e ricerca aziendale. Hai anche competenze eccezionali nella vendita di prodotti software B2B”. Imposterà gli obiettivi da seguire per l’IA (leggi di più qui).
from langchain.chat_models import ChatOpenAIfrom langchain.schema import HumanMessage, SystemMessagedef generate_gpt_response(gpt_input, max_tokens): """Funzione per generare una risposta da GPT-3. Prende input e max token come argomenti e restituisce una risposta""" # Crea un'istanza della classe OpenAI chat = ChatOpenAI(openai_api_key=st.secrets["openai_credentials"]["API_KEY"], model='gpt-3.5-turbo-0613', temperature=0, max_tokens=max_tokens) # Genera una risposta dal modello response = chat.predict_messages( [SystemMessage(content='Sei un esperto disponibile in finanza, mercato e ricerca aziendale.' 'Hai anche competenze eccezionali nella vendita di prodotti software B2B.'), HumanMessage( content=gpt_input)]) return response.content.strip()Successivamente, creiamo un prompt per il modello e invochiamo la funzione generate_gpt_response().
Chiedi al modello di creare un’analisi SWOT di una specifica azienda e restituisci il risultato come un dizionario Python con questo codice:
input_swot = """Crea una breve analisi SWOT dell'azienda {name} con ticker {ticker}?Restituisci l'output come un dizionario Python con le seguenti chiavi: Punti di forza, Punti deboli, Opportunità, Minacce come chiavi e analisi come valori.Non restituire altro."""input_swot = input_swot.format(name='Azienda 1', ticker='ABC')# restituisci la risposta da GPT-3gpt_swot = generate_gpt_response(input_swot, 1000)Il dizionario risultante dovrebbe assomigliare a questo:
{"Punti di forza": "testo", "Punti deboli": "testo", "Opportunità": "testo", "Minacce": "testo"}Allo stesso modo, puoi chiedere al modello GPT di scrivere una proposta di valore per un prodotto specifico per un’azienda data. L’app utilizza il comune framework di proposta di valore per identificare i problemi e i vantaggi dei clienti, nonché i creatori di vantaggi e i sollevatori di problemi:
input_vp = """"Crea una breve proposta di valore utilizzando il framework del Canvas di Proposta di Valore per il prodotto {product} per l'azienda {name} con ticker {ticker} che opera nel settore {industry}.Restituisci l'output come un dizionario Python con le seguenti chiavi: Problemi, Vantaggi, Creatori di vantaggi, Sollevatori di problemi come chiavi e testo come valori. Sii specifico e conciso. Non restituire altro."""input_vp = input_vp.format(product='Software di contabilità', name='Azienda 1', ticker='ABC', industry='Vendita al dettaglio')# restituisci la risposta da GPT-3gpt_value_prop = generate_gpt_response(input_vp, 1000)# la risposta assomiglia a quanto segue: # {"Problemi": "testo", "Vantaggi": "testo", "Creatori di vantaggi": "testo", "Sollevatori di problemi": "testo"}Estrai dati strutturati dalla risposta di GPT
Nel passaggio precedente, hai chiesto al modello GPT un dizionario Python di risposte. Ma poiché gli LLM possono talvolta produrre risposte senza senso, la stringa restituita potrebbe non contenere solo il dizionario necessario. In tali casi, potrebbe essere necessario analizzare la stringa di risposta per estrarre il dizionario e convertirlo nel tipo di dizionario Python.
Per fare ciò, avrai bisogno di due librerie standard: re e ast.
La funzione dict_from_string() prende la stringa di risposta dall’LLM e restituisce un dizionario in questo flusso di lavoro:
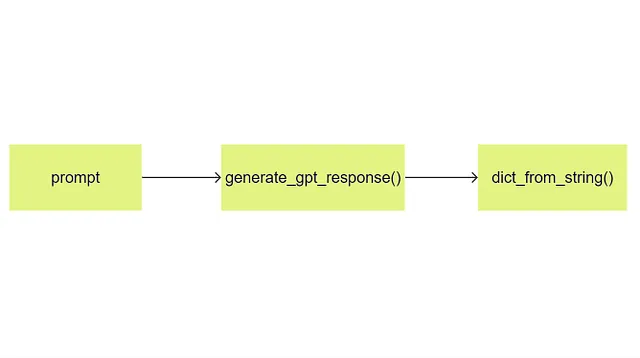
Ecco il codice:
import reimport astdef dict_from_string(gpt_response): """Funzione per analizzare la risposta di GPT e convertirla in un dizionario""" # Trova una sottostringa che inizia con '{' e termina con '}', su più righe match = re.search(r'\\{.*?\\}', gpt_response, re.DOTALL) dictionary = None if match: try: # Prova a convertire la sottostringa in un dizionario dictionary = ast.literal_eval(match.group()) except (ValueError, SyntaxError): # Non è un dizionario return None return dictionaryswot_dict = dict_from_string(gpt_response=gpt_swot)vp_dict = dict_from_string(gpt_response=gpt_value_prop)Genera le diapositive utilizzando python-pptx
Ora che hai i dati, è ora di compilare le diapositive. Utilizza un modello di PowerPoint e sostituisci i segnaposto con valori reali utilizzando la libreria python-pptx.
Ecco come dovrebbe apparire il modello di diapositive SWOT:

Per popolare la diapositiva con i dati, utilizza la funzione replace_text(), che richiede due argomenti:
- Un dizionario con i segnaposto come chiavi e il testo di sostituzione come valori
- Un oggetto di diapositiva di PowerPoint
Utilizza la variabile swot_dict definita nel passaggio precedente:
from pptx import Presentationdef replace_text(replacements, slide): """funzione per sostituire il testo in una diapositiva di PowerPoint. Prende un dizionario di {corrispondenza: sostituzione, ...} e sostituisce tutte le corrispondenze""" # Itera su tutte le forme nella diapositiva for shape in slide.shapes: for match, replacement in replacements.items(): if shape.has_text_frame: if (shape.text.find(match)) != -1: text_frame = shape.text_frame for paragraph in text_frame.paragraphs: whole_text = "".join(run.text for run in paragraph.runs) whole_text = whole_text.replace(str(match), str(replacement)) for idx, run in enumerate(paragraph.runs): if idx != 0: p = paragraph._p p.remove(run._r) if bool(paragraph.runs): paragraph.runs[0].text = whole_textprs = Presentation("template.pptx")swot_slide = prs.slides[2]# crea il titolo delle diapositiveswot_title = 'Analisi SWOT di {}'.format('Azienda 1')# inizializza un dizionario di segnaposti e valori da sostituirereplaces_dict = { '{s}': swot_dict['Forze'], '{w}': swot_dict['Debolezze'], '{o}': swot_dict['Opportunità'], '{t}': swot_dict['Minacce'], '{swot_title}': swot_title}# esegui la funzione per sostituire i segnaposti con i valorireplace_text(replacements=replaces_dict, slide=swot_slide)In breve, la funzione replace_text() itera su tutte le forme di una diapositiva, cercando i valori dei segnaposto e li sostituisce con i valori del dizionario se trovati.
Una volta che tutte le diapositive sono state riempite con dati o immagini, l’oggetto di presentazione viene salvato come output binario e passato a st.download_button() in modo che un utente possa scaricare un file PowerPoint (leggi di più qui).
Ecco come dovrebbe apparire il pulsante di download nell’interfaccia utente:
Ecco qui il codice:
from pptx import Presentation
from io import BytesIO
from datetime import date
import streamlit as st
# crea il nome del file
filename = '{name} {date}.pptx'.format(name='Azienda 1', date=date.today())
# salva la presentazione come output binario
binary_output = BytesIO()
prs.save(binary_output)
# mostra un messaggio di successo e un pulsante per il download
st.success('Le diapositive sono state generate! :tada:')
st.download_button(label='Clicca per scaricare la presentazione', data=binary_output.getvalue(), file_name=filename)Vedi la presentazione di esempio qui.
Conclusione
Grazie per aver letto fino alla fine! Ora puoi sviluppare un’app di automazione delle diapositive per la ricerca aziendale utilizzando Streamlit, Snowflake, YahooFinance e LangChain. Spero che tu abbia trovato qualcosa di nuovo e utile in questo articolo.
Come puoi vedere, ci sono alcune limitazioni nell’app. In primo luogo, genera solo ricerche su aziende pubbliche. In secondo luogo, il modello GPT utilizza conoscenze generali su un prodotto, come ChatBot o Software di Contabilità, per scrivere una proposta di valore. In un’app più avanzata, il secondo vincolo potrebbe essere affrontato affinando il modello con i dati del tuo prodotto. Ciò può essere fatto passando i dettagli del tuo prodotto come prompt o memorizzando questi dati come embedding in un database vettoriale (leggi di più qui).
Se hai domande o feedback, per favore lasciali nei commenti qui sotto o contattami su GitHub, LinkedIn o Twitter.
- Un dizionario con segnaposto come chiavi e testo di sostituzione come valori
- Un oggetto di diapositiva PowerPoint
Utilizza la variabile swot_dict definita nel passaggio precedente:






