Addestriamo le nostre macchine, poi loro ci addestrano la natura ricorsiva della costruzione dell’IA
Addestriamo le macchine, poi loro addestrano la natura ricorsiva dell'IA.
Il 10 maggio 1941, le bombe tedesche ridussero l’illustre House of Commons britannica in rovine fumanti; il famoso complesso di revival gotico era rimasto in piedi per oltre due secoli come sfondo per un vigoroso dibattito politico, eppure ora questo simbolo architettonico giaceva in cenere. Tra il fumo, emerse una domanda pressante: ricostruire identico al passato o abbracciare ridisegni moderni come le ampie sale semicircolari trovate all’estero? Per Winston Churchill, la risposta era chiara. In un discorso del 1943, osservò: “Noi modelliamo i nostri edifici, e successivamente i nostri edifici ci modellano“, credendo che l’intimità confrontazionale della vecchia camera fosse intrecciata nell’anima rumorosa della democrazia britannica.

A differenza degli ampi spazi legislativi stranieri (come il layout semicircolare del Campidoglio degli Stati Uniti), la vecchia Commons comprimeva 427 posti strettamente insieme, mettendo faccia a faccia fazioni opposte attraverso un corridoio stretto senza nascondigli. Lo spirito democratico era alimentato da una confrontazione diretta che portava a responsabilità. Sebbene potesse essere rumoroso e disordinato, era autentico. Nonostante fosse aperto a miglioramenti funzionali, Churchill ha spinto per il ripristino dell’arena. Nonostante la distruzione, la conservazione della forma che aveva ospitato secoli di dibattiti clamorosi era prioritaria.
Il sentimento di Churchill – che gli spazi costruiti modellano la vita collettiva – va oltre il design degli edifici. Questa nozione, talvolta chiamata “determinismo architettonico”, suggerisce che il nostro ambiente costruito influenzi profondamente il comportamento umano. I pianificatori urbani applicano questi principi deliberatamente, allargando i marciapiedi per favorire l’attività dei pedoni lungo i boulevard delle città. O considera un pittoresco ponte a un’unica corsia sopra un ruscello tortuoso: la sua strettezza promuove pazienza e cooperazione mentre i conducenti aspettano cortesemente il loro turno per attraversare.
- LLM Strumento Trova e Rimuove Vulnerabilità del Software
- 10 migliori strumenti generatore di immagini AI da utilizzare nel 2023
- Platypus Curazione dei dataset e adattatori per modelli di linguaggio di grandi dimensioni migliori
Nell’era digitale, il determinismo architettonico si manifesta attraverso le scelte fatte nella costruzione dei sistemi di intelligenza artificiale, che plasmeranno la struttura stessa del discorso mentre i grandi modelli di linguaggio permeano la società.
Plasmare i Nostri Assistenti: Insegnare l’IA Attraverso il Feedback Umano
Quando OpenAI ha presentato GPT-2 nel 2019, il modello di linguaggio naturale rappresentava un balzo in avanti. Allenato su 40 GB di testo di Internet attraverso l’apprendimento non supervisionato, i suoi 1,5 miliardi di parametri potevano generare passaggi sorprendentemente coerenti. Tuttavia, rimanevano delle incongruenze. Senza una guida umana, la potenza impressionante ma senza scopo di GPT-2 produceva divagazioni prolisse tanto quanto informazioni utili.
Per affinare la loro creazione, OpenAI ha introdotto un nuovo approccio: il reinforcement learning dal feedback umano (RLHF). La tecnica, descritta nel documento “Fine-tuning Language Models from Human Feedback”, unisce l’intuizione umana all’IA per guidare i modelli verso comportamenti più “utili”.
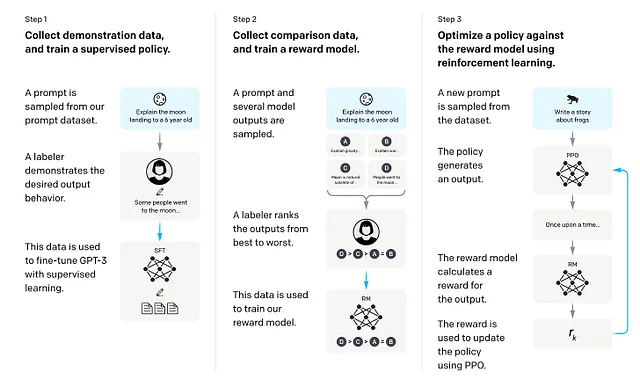
Ecco come funziona: partendo da un modello di base come GPT-2, gli allenatori umani interagiscono con il sistema, interpretando sia l’utente che l’IA. Questa conversazione crea un set di dati che riflette le preferenze umane. Gli allenatori poi plasmano ulteriormente il modello classificando le sue risposte campione, consentendo lo sviluppo di un “modello di ricompensa” che valuta l’output in base alla qualità. L’IA migliora progressivamente affinando il modello per massimizzare le sue ricompense, generando testo più allineato ai valori umani. Attraverso cicli di feedback e perfezionamento, RLHF trasforma modelli una volta erratici in compagni più utili e mirati.
I frutti di questo approccio sono arrivati con ChatGPT nel 2022. Allenato utilizzando RLHF, ha stupito gli utenti con risposte riflessive e conversazionali.
Il Costo Alto della Saggezza Umana
Dopo la svolta di ChatGPT, altri laboratori di intelligenza artificiale hanno rapidamente adottato il reinforcement learning dal feedback umano (RLHF). Aziende come DeepMind, Anthropic e Meta si sono basate su RLHF per creare assistenti come Sparrow, Claude e LLaMA-2-chat.
Tuttavia, sebbene efficace, RLHF richiede risorse immense. Ogni round coinvolge allenatori umani che generano conversazioni, valutano le risposte e forniscono orientamenti su larga scala. Per GPT-3, OpenAI ha esternalizzato questo processo laborioso a fornitori in Kenya. Il sostegno finanziario della “non-profit” ha reso possibile questo approccio basato sull’intervento umano, ma tali costi limitano l’accessibilità per molti.
![Sistema di addestramento di Anthropic dal loro articolo “[2204.05862] Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback”](https://miro.medium.com/v2/resize:fit:640/format:webp/0*RKcXOghubZb_Zzzi.png)
Alcune organizzazioni stanno cercando soluzioni creative per superare l’ostacolo. Il progetto Open Assistant invita il pubblico a contribuire direttamente alla formazione del modello attraverso una piattaforma di crowdsourcing. DataBricks ha reso il processo ludico internamente, incoraggiando i suoi 5.000 dipendenti a valutare interazioni di esempio attraverso un’interfaccia web divertente. Ciò ha permesso loro di creare rapidamente il set di dati per il proprio assistente, Dolly. Start-up come Scale AI offrono anche servizi per gestire l’annotazione umana necessaria per RLHF.
Copiare i compagni di classe: utilizzare LLM per avviarsi a vicenda
Poiché il prezzo proibitivo di RLHF scoraggia molti, alcuni ricercatori stanno riducendo i costi sostituendo il feedback umano con l’output di altri modelli linguistici.
Il gruppo di Intelligenza Artificiale centrata sull’Uomo di Stanford ha dimostrato questa scorciatoia. Nel tentativo di riprogettare i 7 miliardi di parametri di LLaMA di Meta in un assistente più capace come ChatGPT, hanno scritto 175 attività di base e utilizzato il modello DaVinci di OpenAI per generare un set di dati di 52.000 esempi al costo di soli $500. Invece dell’annotazione umana accurata, davinci ha prodotto automaticamente dati etichettati. Il raffinamento di LLaMA su questo set di dati sintetico ha creato Alpaca-7B, un assistente abile, per un totale di soli $600.
Ricercatori dell’UC Berkeley hanno collaborato per addestrare il modello Vicuna con 13 miliardi di parametri utilizzando 70.000 conversazioni prese da ShareGPT (un sito web in cui le persone condividono le loro discussioni con ChatGPT). Vicuna ha raggiunto il 90% delle prestazioni di ChatGPT, addestrato su dati a una frazione del costo.
Nel frattempo, Microsoft e l’Università di Pechino hanno sviluppato Evol-Instruct, un nuovo metodo per far crescere in modo esponenziale i dati di base utilizzando un LLM. Il loro risultante WizardLM supera persino GPT-4 in determinate competenze, dimostrando la potenza dei set di dati sintetici.
Set di dati open-source come le 1,2 trilioni di repliche di token LLaMA di RedPajama mirano anche a democratizzare la formazione dei modelli.
Diventiamo ciò che contempliamo. Modelliamo i nostri strumenti e poi i nostri strumenti ci modellano
Churchill ha capito secoli fa come gli spazi costruiti plasmino le norme collettive. La sua intuizione risuona ancora una volta mentre gli LLM proliferano attraverso cicli di addestramento sintetici. Le scelte architettoniche fatte in quei modelli iniziali si propagano mentre il loro output addestra nuove generazioni. Le prime imperfezioni e i pregiudizi si ripercuotono sottilmente nel tempo, modellando il discorso stesso.
Quando gli LLM generano testi letti da milioni di persone ogni giorno, le loro idiosincrasie permeano l’espressione umana. Mentre i modelli ottimizzati per una chat coinvolgente consigliano gli scrittori, le loro tendenze influenzano i contenuti pubblicati. I nostri strumenti riflettono i nostri valori e, nel tempo, ci rimodellano a loro immagine.
Ma questa danza tra creatore e creazione non è anormale, è la storia del progresso umano. Dalla stampa alla televisione, le invenzioni sono sempre tornate a influenzare i loro creatori. Gli LLM sono solo l’ultima invenzione a plasmare la società come essa stessa ci plasma.