Accelerare la gestione del successo del cliente attraverso la classificazione delle email con Hugging Face su Amazon SageMaker
Accelerare la gestione del successo del cliente con Hugging Face su Amazon SageMaker
Questo è un post degli ospiti di Scalable Capital, un’azienda leader nel settore delle tecnologie finanziarie in Europa che offre servizi di gestione patrimoniale digitale e una piattaforma di brokerage con un tasso di commissione fissa per il trading.
Come azienda in rapida crescita, gli obiettivi di Scalable Capital sono non solo di costruire un’infrastruttura innovativa, robusta e affidabile, ma anche di fornire le migliori esperienze ai nostri clienti, soprattutto per quanto riguarda i servizi clienti.
Scalable riceve centinaia di richieste di informazioni via email dai nostri clienti ogni giorno. Implementando un moderno modello di elaborazione del linguaggio naturale (NLP), il processo di risposta è stato reso molto più efficiente e i tempi di attesa per i clienti sono stati ridotti notevolmente. Il modello di apprendimento automatico (ML) classifica le nuove richieste dei clienti in arrivo non appena arrivano e le indirizza alle code predefinite, consentendo ai nostri agenti dedicati al successo del cliente di concentrarsi sui contenuti delle email in base alle loro competenze e fornire risposte appropriate.
In questo post, dimostriamo i vantaggi tecnici dell’utilizzo dei trasformatori di Hugging Face implementati con Amazon SageMaker, come addestramento e sperimentazione su larga scala, e aumento della produttività ed efficienza dei costi.
- Superare le barriere linguistiche tradurre i log dell’applicazione con Amazon Translate per un supporto senza soluzione di continuità
- Amazon SageMaker semplifica la configurazione di Amazon SageMaker Studio per gli utenti singoli
- Un potenziamento quantistico cuQuantum con PennyLane permette alle simulazioni di viaggiare sui supercomputer
Problema
Scalable Capital è una delle società fintech in più rapida crescita in Europa. Con l’obiettivo di democratizzare gli investimenti, l’azienda offre ai propri clienti un facile accesso ai mercati finanziari. I clienti di Scalable possono partecipare attivamente al mercato attraverso la piattaforma di trading di brokerage dell’azienda o utilizzare Scalable Wealth Management per investire in modo intelligente e automatizzato. Nel 2021, Scalable Capital ha registrato un aumento di dieci volte della propria base clienti, passando da decine di migliaia a centinaia di migliaia.
Per fornire ai nostri clienti un’esperienza utente di alto livello (e coerente) su prodotti e servizi clienti, l’azienda stava cercando soluzioni automatizzate per generare efficienze per una soluzione scalabile mantenendo al contempo l’eccellenza operativa. I team di data science e servizio clienti di Scalable Capital hanno identificato che uno dei principali ostacoli nel servire i nostri clienti era la risposta alle richieste di informazioni via email. In particolare, l’ostacolo era il passaggio di classificazione, in cui i dipendenti dovevano leggere ed etichettare i testi delle richieste quotidianamente. Dopo che le email venivano reindirizzate alle code appropriate, gli specialisti risolvevano rapidamente i casi.
Per semplificare questo processo di classificazione, il team di data science di Scalable ha costruito e implementato un modello NLP multitask utilizzando un’architettura di trasformatori all’avanguardia, basata sul modello preaddestrato distilbert-base-german-cased pubblicato da Hugging Face. distilbert-base-german-cased utilizza il metodo di distillazione delle conoscenze per preaddestrare un modello di rappresentazione del linguaggio più piccolo e generico rispetto al modello BERT base originale. La versione distillata ottiene prestazioni comparabili alla versione originale, pur essendo più piccola e più veloce. Per facilitare il nostro processo del ciclo di vita dell’apprendimento automatico, abbiamo deciso di adottare SageMaker per la costruzione, l’implementazione, il servizio e il monitoraggio dei nostri modelli. Nella sezione seguente, presentiamo la progettazione dell’architettura del nostro progetto.
Panoramica della soluzione
L’infrastruttura di ML di Scalable Capital è composta da due account AWS: uno come ambiente per la fase di sviluppo e l’altro per la fase di produzione.
Il diagramma seguente mostra il flusso di lavoro per il nostro progetto di classificazione delle email, ma può essere generalizzato anche ad altri progetti di data science.
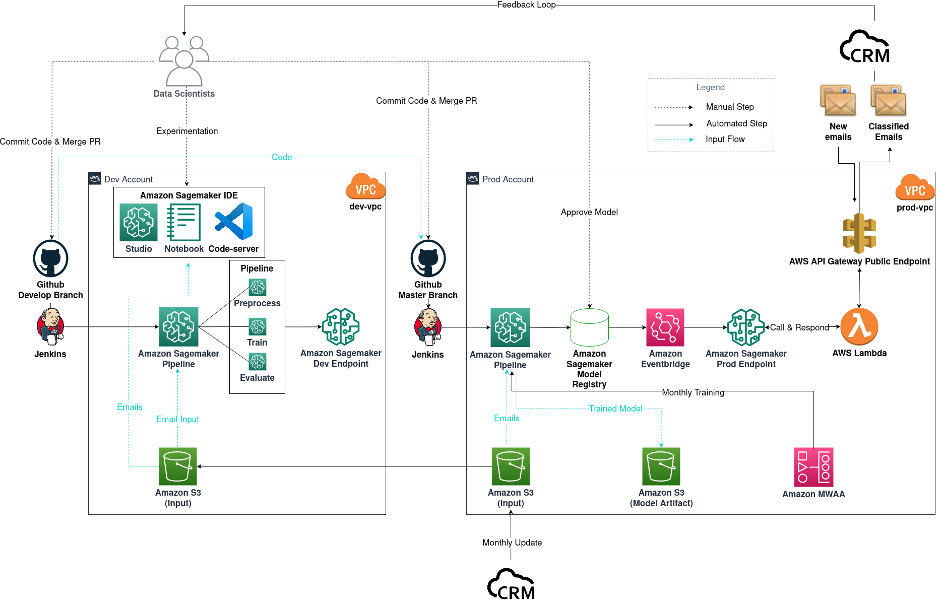
Diagramma del progetto di classificazione delle email
Il flusso di lavoro è composto dai seguenti componenti:
- Sperimentazione del modello – I data scientist utilizzano Amazon SageMaker Studio per svolgere i primi passi nel ciclo di vita del data science: analisi esplorativa dei dati (EDA), pulizia e preparazione dei dati e costruzione di modelli prototipo. Quando la fase esplorativa è completa, passiamo a VSCode ospitato da un notebook di SageMaker come nostro strumento di sviluppo remoto per modularizzare e produrre in modo professionale il nostro codice. Per esplorare diversi tipi di modelli e configurazioni di modelli, e contemporaneamente per tenere traccia delle nostre sperimentazioni, utilizziamo SageMaker Training e SageMaker Experiments.
- Costruzione del modello – Dopo aver deciso un modello per il nostro caso d’uso di produzione, in questo caso un modello distilbert-base-german-cased multi-task, ottimizzato dal modello preaddestrato di Hugging Face, committiamo e pushiamo il nostro codice nel branch di sviluppo di Github. L’evento di merge di Github attiva la nostra pipeline di CI di Jenkins, che a sua volta avvia un processo di SageMaker Pipelines con dati di test. Questo funge da test per verificare che il codice funzioni come previsto. Viene inoltre implementato un endpoint di test a scopo di verifica.
- Implementazione del modello – Dopo aver verificato che tutto funzioni come previsto, i data scientist effettuano il merge del branch di sviluppo nel branch principale. Questo evento di merge attiva ora un processo di SageMaker Pipelines utilizzando dati di produzione per scopi di addestramento. Successivamente, vengono prodotti artefatti del modello e archiviati in un bucket di Amazon Simple Storage Service (Amazon S3) di output e una nuova versione del modello viene registrata nel registro dei modelli di SageMaker. I data scientist esaminano le prestazioni del nuovo modello, quindi lo approvano se è in linea con le aspettative. L’evento di approvazione del modello viene catturato da Amazon EventBridge, che quindi implementa il modello su un endpoint di SageMaker nell’ambiente di produzione.
- MLOps – Poiché l’endpoint di SageMaker è privato e non può essere raggiunto da servizi al di fuori della VPC, è necessaria una funzione AWS Lambda e un endpoint pubblico di Amazon API Gateway per comunicare con il CRM. Ogni volta che arrivano nuove email nella casella di posta del CRM, il CRM invoca l’endpoint pubblico di API Gateway, che a sua volta attiva la funzione Lambda per invocare l’endpoint privato di SageMaker. La funzione comunica quindi la classificazione al CRM tramite l’endpoint pubblico di API Gateway. Per monitorare le prestazioni del nostro modello implementato, viene creato un ciclo di feedback tra il CRM e i data scientist per tenere traccia delle metriche di previsione del modello. Mensilmente, il CRM aggiorna i dati storici utilizzati per sperimentazione e addestramento del modello. Utilizziamo Amazon Managed Workflows for Apache Airflow (Amazon MWAA) come scheduler per il nostro riaddestramento mensile.
Nelle sezioni seguenti, analizziamo più dettagliatamente i passaggi di preparazione dei dati, sperimentazione del modello e distribuzione del modello.
Preparazione dei dati
Scalable Capital utilizza un CRM per la gestione e l’archiviazione dei dati delle email. I contenuti delle email pertinenti consistono di oggetto, corpo e banche custodi. Ci sono tre etichette da assegnare a ciascuna email: da quale settore l’email proviene, quale coda è appropriata e l’argomento specifico dell’email.
Prima di iniziare ad addestrare modelli NLP, ci assicuriamo che i dati di input siano puliti e che le etichette siano assegnate secondo le aspettative.
Per recuperare i contenuti delle richieste pulite dai clienti di Scalable, rimuoviamo dai dati delle email grezze testo e simboli extra, come firme email, impressum, citazioni di messaggi precedenti nelle catene di email, simboli CSS, e così via. Altrimenti, i nostri modelli addestrati in futuro potrebbero subire una riduzione delle prestazioni.
Le etichette per le email evolvono nel tempo a mano che i team del servizio clienti di Scalable ne aggiungono di nuove e ne affinano o eliminano di esistenti per soddisfare le esigenze aziendali. Per assicurarsi che le etichette per i dati di addestramento e le classificazioni previste siano aggiornate, il team di data science collabora strettamente con il team del servizio clienti per garantire la correttezza delle etichette.
Sperimentazione del modello
Iniziamo il nostro esperimento con il modello pre-addestrato distilbert-base-german-cased pubblicato da Hugging Face. Poiché il modello pre-addestrato è un modello di rappresentazione del linguaggio a scopo generale, possiamo adattare l’architettura per eseguire specifiche attività successive, come classificazione e risposta a domande, collegando teste appropriate alla rete neurale. Nel nostro caso d’uso, l’attività successiva di nostro interesse è la classificazione delle sequenze. Senza modificare l’architettura esistente, decidiamo di affinare tre modelli pre-addestrati separati per ciascuna delle nostre categorie richieste. Con i container Deep Learning di SageMaker Hugging Face (DLC), l’avvio e la gestione degli esperimenti NLP sono semplificati grazie ai container Hugging Face e all’API SageMaker Experiments.
Di seguito è riportato un frammento di codice di train.py:
config = AutoConfig.from_pretrained("distilbert-base-german-cased") # carica la configurazione originale
config.num_labels = num_labels # adatta la configurazione originale a un numero specifico di etichette (il valore predefinito è 2)
# istanzia un modello pre-addestrato
model = DistilBertForSequenceClassification.from_pretrained("distilbert-base-german-cased", config=config)
trainer = Trainer(
model=model, # il modello Transformers istanziato da addestrare
args=training_args, # argomenti di addestramento, definiti in precedenza
train_dataset=train_dataset, # dataset di addestramento
eval_dataset=val_dataset # dataset di valutazione
)
trainer.train()Il seguente codice è l’estimatore Hugging Face:
huggingface_estimator = HuggingFace(
entry_point='train.py',
source_dir='./scripts',
instance_type='ml.p3.2xlarge',
instance_count=1,
role=role,
transformers_version='4.26.0',
pytorch_version='1.13.1',
py_version='py39',
hyperparameters = hyperparameters
)Per convalidare i modelli affinati, utilizziamo l’F1-score a causa della natura sbilanciata del nostro set di dati delle email, ma anche per calcolare altre metriche come l’accuratezza, la precisione e il richiamo. Affinché l’API degli esperimenti di SageMaker registri le metriche del job di addestramento, è necessario prima registrare le metriche sulla console locale del job di addestramento, che vengono prese da Amazon CloudWatch. Quindi definiamo il formato regex corretto per catturare i log di CloudWatch. Le definizioni delle metriche includono il nome delle metriche e la validazione regex per estrarre le metriche dal job di addestramento:
metric_definitions = [
{"Name": "train:loss", "Regex": "'loss': ([0-9]+(.|e\-)[0-9]+),?"},
{"Name": "learning_rate", "Regex": "'learning_rate': ([0-9]+(.|e\-)[0-9]+),?"},
{"Name": "val:loss", "Regex": "'eval_loss': ([0-9]+(.|e\-)[0-9]+),?"},
{"Name": "train:accuracy", "Regex": "'train_accuracy': ([0-9]+(.|e\-)[0-9]+),?"},
{"Name": "val:accuracy", "Regex": "'eval_accuracy': ([0-9]+(.|e\-)[0-9]+),?"},
{"Name": "train:precision", "Regex": "'train_precision': ([0-9]+(.|e\-)[0-9]+),?"},
{"Name": "val:precision", "Regex": "'eval_precision': ([0-9]+(.|e\-)[0-9]+),?"},
{"Name": "train:recall", "Regex": "'train_recall': ([0-9]+(.|e\-)[0-9]+),?"},
{"Name": "val:recall", "Regex": "'eval_recall': ([0-9]+(.|e\-)[0-9]+),?"},
{"Name": "train:f1", "Regex": "'train_f1': ([0-9]+(.|e\-)[0-9]+),?"},
{"Name": "val:f1", "Regex": "'eval_f1': ([0-9]+(.|e\-)[0-9]+),?"},
{"Name": "val:runtime", "Regex": "'eval_runtime': ([0-9]+(.|e\-)[0-9]+),?"},
{"Name": "val:samples_per_second", "Regex": "'eval_samples_per_second': ([0-9]+(.|e\-)[0-9]+),?"},
{"Name": "epoch", "Regex": "'epoch': ([0-9]+(.|e\-)[0-9]+),?"},
]Come parte dell’iterazione di addestramento per il modello di classificazione, utilizziamo una matrice di confusione e un rapporto di classificazione per valutare il risultato. La figura seguente mostra la matrice di confusione per la previsione della linea di business.
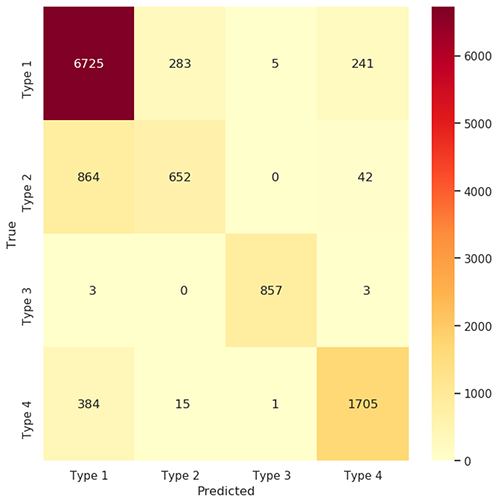
Matrice di Confusione
La seguente schermata mostra un esempio del rapporto di classificazione per la previsione della linea di business.
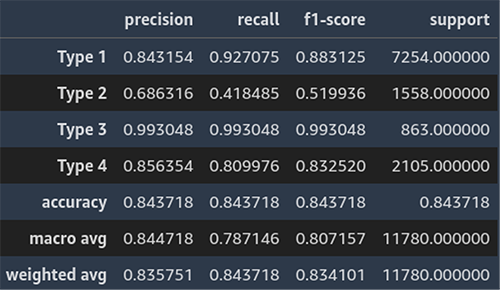
Rapporto di Classificazione
Come prossima iterazione del nostro esperimento, sfrutteremo l’apprendimento multi-task per migliorare il nostro modello. L’apprendimento multi-task è una forma di addestramento in cui un modello impara a risolvere contemporaneamente più compiti, poiché le informazioni condivise tra i compiti possono migliorare l’efficienza dell’apprendimento. Attaccando due ulteriori “classification head” all’architettura distilbert originale, possiamo eseguire il fine-tuning multi-task, che ottiene metriche ragionevoli per il nostro team di servizio clienti.
Deploy del Modello
Nel nostro caso d’uso, il classificatore di email deve essere deployato su un endpoint, al quale il nostro pipeline CRM può inviare un batch di email non classificate e ottenere le previsioni. Poiché abbiamo altre logiche, come la pulizia dei dati in input e le previsioni multi-task, oltre all’inferenza del modello Hugging Face, dobbiamo scrivere uno script di inferenza personalizzato che rispetti lo standard di SageMaker.
Di seguito è riportato un frammento di codice di inference.py:
def model_fn(model_dir):
model = load_from_artifact(model_dir)
return model
def transform_fn(model, input_data, content_type, accept):
if content_type == "application/json":
data = json.loads(input_data)
data = pd.DataFrame(data)
else:
raise ValueError(f"Tipo di contenuto non supportato: {content_type}")
data = preprocess(data)
# Inferenza
with torch.no_grad():
predictions = model(data)
predictions = postprocess(predictions)
if content_type == 'application/json':
return json.dumps(predictions.to_dict(orient="records"))
else:
raise NotImplementedErrorQuando tutto è pronto, utilizziamo SageMaker Pipelines per gestire la nostra pipeline di addestramento e la collegiamo alla nostra infrastruttura per completare la nostra configurazione di MLOps.
Per monitorare le prestazioni del modello deployato, creiamo un ciclo di feedback che consente al CRM di fornirci lo stato delle email classificate quando i casi vengono chiusi. Basandoci su queste informazioni, apportiamo modifiche per migliorare il modello deployato.
Conclusioni
In questo post, abbiamo condiviso come SageMaker facilita il team di data science di Scalable nella gestione del ciclo di vita di un progetto di data science in modo efficiente, ovvero il progetto di classificazione delle email. Il ciclo di vita inizia con la fase iniziale di analisi ed esplorazione dei dati con SageMaker Studio; passa all’esperimento e al deploy del modello con SageMaker training, inferenza e Hugging Face DLCs; e si completa con una pipeline di addestramento con SageMaker Pipelines integrato con altri servizi AWS. Grazie a questa infrastruttura, siamo in grado di iterare e deployare nuovi modelli in modo più efficiente e pertanto migliorare i processi esistenti all’interno di Scalable e l’esperienza dei nostri clienti.
Per saperne di più su Hugging Face e SageMaker, consulta le risorse seguenti:
- Usa Hugging Face con Amazon SageMaker
- Cos’è AWS Deep Learning Containers?
- Usa la versione 2.x del SageMaker Python SDK: Frameworks: Hugging Face