Un’immersione profonda nei modelli GPT Evoluzione e Confronto delle Prestazioni
A deep dive into GPT models Evolution and Performance Comparison.
Il blog si concentra sui modelli GPT, fornendo una comprensione e un’analisi approfondita. Spiega i tre componenti principali dei modelli GPT generativi, pre-addestrati e trasformatori.
Da Ankit, Bhaskar e Malhar
Negli ultimi anni, c’è stato un notevole progresso nel campo dell’Elaborazione del Linguaggio Naturale, grazie all’emergere di grandi modelli linguistici. I modelli linguistici sono utilizzati nei sistemi di traduzione automatica per imparare come mappare le stringhe da una lingua all’altra. Tra la famiglia di modelli linguistici, il modello basato su Generative Pre-trained Transformer (GPT) ha attirato maggiormente l’attenzione negli ultimi tempi. Inizialmente, i modelli linguistici erano sistemi basati su regole che dipendevano pesantemente dall’input umano per funzionare. Tuttavia, l’evoluzione delle tecniche di apprendimento profondo ha positivamente influenzato la complessità, la scala e l’accuratezza dei compiti gestiti da questi modelli.
Nel nostro blog precedente, abbiamo fornito una spiegazione esaustiva dei vari aspetti del modello GPT3, valutato le funzionalità offerte dall’API GPT-3 di Open AI ed esplorato anche l’utilizzo e le limitazioni del modello. In questo blog, sposteremo il nostro focus sul modello GPT e sui suoi componenti fondamentali. Esploreremo anche l’evoluzione – partendo dal GPT-1 fino al recentemente introdotto GPT-4 e approfondiremo le principali migliorie apportate in ogni generazione che hanno reso i modelli potenti nel tempo.
- Presentiamo MPT-7B un nuovo LLM open-source
- LLM Apocalypse Now La Vendetta dei Cloni Open Source
- Apprendimento Profondo con R
1. Comprensione dei modelli GPT
GPT (Generative Pre-trained Transformers) è un modello di apprendimento profondo basato su un grande modello linguistico (LLM), che utilizza un’architettura di sola decodifica costruita sui transformers. Il suo scopo è elaborare i dati di testo e generare un output di testo che assomiglia al linguaggio umano.
Come suggerisce il nome, ci sono tre pilastri del modello, ovvero:
- Generativo
- Pre-allenato
- Transformers
Esploriamo il modello attraverso questi componenti:
Generativo: Questa funzione enfatizza l’abilità del modello di generare testo comprendendo e rispondendo ad un determinato campione di testo. Prima dei modelli GPT, l’output di testo veniva generato riorganizzando o estraendo parole dall’input stesso. La capacità generativa dei modelli GPT ha dato loro un vantaggio sui modelli esistenti, consentendo la produzione di testo più coerente e simile all’umano.
Questa capacità generativa deriva dall’obiettivo di modellizzazione utilizzato durante la formazione.
I modelli GPT sono addestrati utilizzando la modellizzazione del linguaggio auto-regressivo, in cui i modelli vengono alimentati con una sequenza di parole di input, e il modello cerca di trovare la parola o la frase più adatta utilizzando distribuzioni di probabilità per prevedere la parola o la frase più probabile.
Pre-allenato: “Pre-allenato” si riferisce ad un modello di apprendimento automatico che ha subito un addestramento su un grande dataset di esempi prima di essere implementato per un compito specifico. Nel caso di GPT, il modello viene addestrato su un esteso corpus di dati di testo utilizzando un approccio di apprendimento non supervisionato. Ciò consente al modello di apprendere modelli e relazioni all’interno dei dati senza una guida esplicita.
In termini più semplici, l’addestramento del modello con vaste quantità di dati in modo non supervisionato lo aiuta a comprendere le caratteristiche generali e la struttura di un linguaggio. Una volta appreso, il modello può sfruttare questa comprensione per compiti specifici come la risposta alle domande e la sintesi.
Transformers: Un tipo di architettura di rete neurale progettata per gestire sequenze di testo di lunghezza variabile. Il concetto di transformers ha guadagnato importanza dopo la pubblicazione del rivoluzionario articolo intitolato “Attention Is All You Need” nel 2017.
GPT utilizza un’architettura di sola decodifica. Il componente principale di un transformer è il suo “meccanismo di auto-attenzione”, che consente al modello di catturare la relazione tra ogni parola e le altre parole all’interno della stessa frase.
Esempio:
- Un cane è seduto sulla riva del fiume Gange.
- Prenderò dei soldi dalla banca.
L’auto-attenzione valuta ogni parola in relazione alle altre parole nella frase. Nel primo esempio, quando “banca” viene valutata nel contesto di “fiume”, il modello apprende che si riferisce ad una riva di un fiume. Allo stesso modo, nel secondo esempio, valutando “banca” rispetto alla parola “soldi” suggerisce una banca finanziaria.
2. Evoluzione dei modelli GPT
Adesso, analizziamo più da vicino le varie versioni dei modelli GPT, con un focus sugli miglioramenti e le aggiunte introdotte in ogni modello successivo. 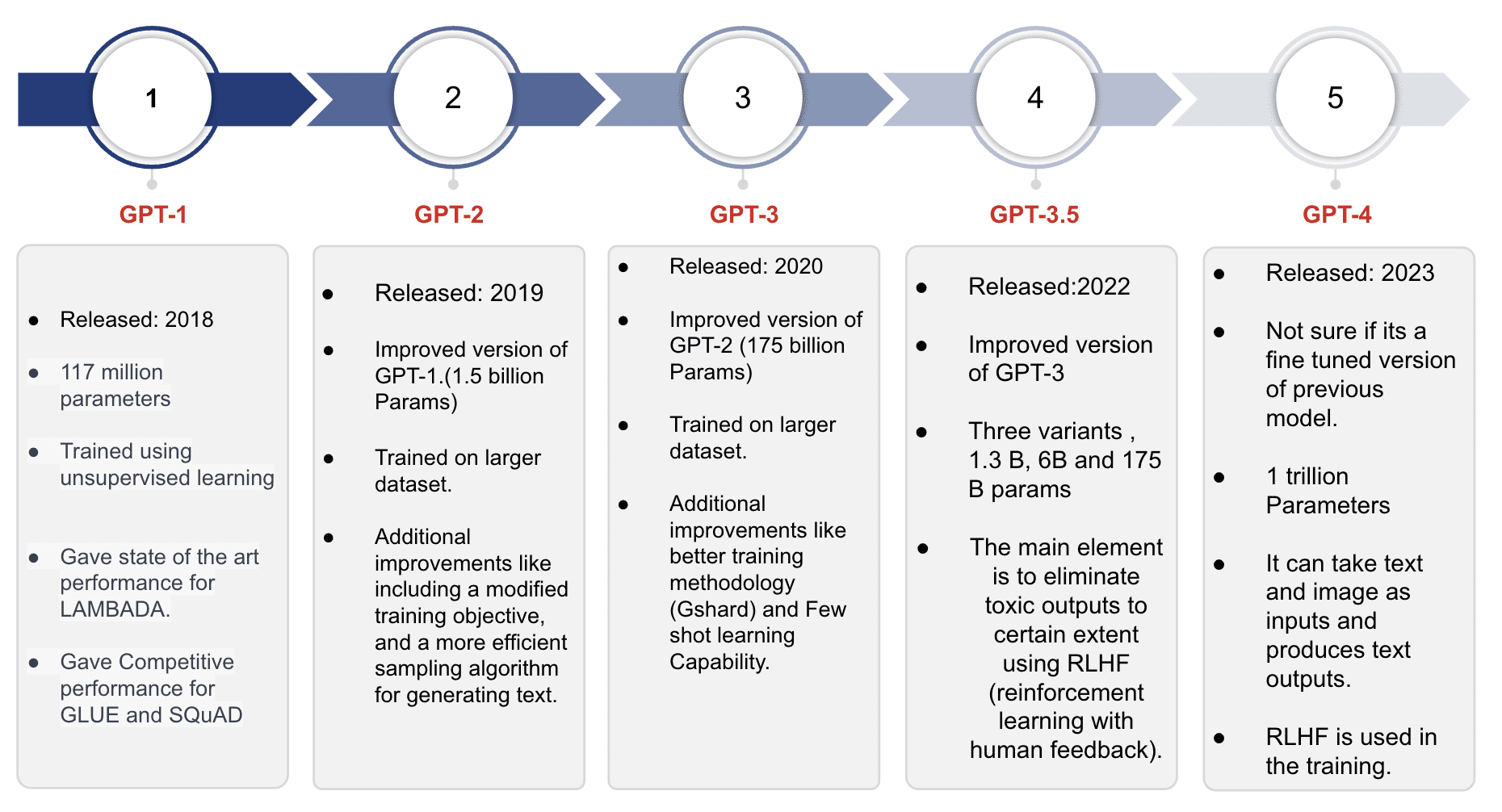
GPT-1
È il primo modello della serie GPT ed è stato addestrato su circa 40GB di dati di testo. Il modello ha raggiunto risultati all’avanguardia per i compiti di modellizzazione come LAMBADA e ha dimostrato una performance competitiva per compiti come GLUE e SQuAD. Con una lunghezza massima del contesto di 512 token (circa 380 parole), il modello poteva conservare le informazioni per frasi o documenti relativamente brevi per richiesta. Le impressionanti capacità di generazione di testo del modello e la sua forte performance sui compiti standard hanno fornito lo spunto per lo sviluppo del successivo modello della serie.
GPT-2
Derivato dal modello GPT-1, il Modello GPT-2 mantiene le stesse caratteristiche architetturali. Tuttavia, è sottoposto a training su un corpus di dati testuali ancora più ampio rispetto a GPT-1. In particolare, GPT-2 può ospitare il doppio della dimensione dell’input, consentendogli di elaborare campioni di testo più estesi. Con quasi 1,5 miliardi di parametri, GPT-2 presenta un notevole aumento di capacità e potenziale per il modeling del linguaggio.
Ecco alcuni dei principali miglioramenti di GPT-2 rispetto a GPT 1:
- Training dell’obiettivo modificato è una tecnica utilizzata durante la fase di pre-training per migliorare i modelli linguistici. Tradizionalmente, i modelli prevedono la parola successiva nella sequenza solo in base alle parole precedenti, portando a previsioni potenzialmente incoerenti o non pertinenti. L’allenamento MO affronta questa limitazione incorporando contesto aggiuntivo, come parti del discorso (sostantivo, verbo, ecc.) e identificazione soggetto-oggetto. Sfruttando queste informazioni supplementari, il modello genera output più coerenti e informativi.
- Normalizzazione del layer è un’altra tecnica impiegata per migliorare l’addestramento e le prestazioni. Consiste nella normalizzazione delle attivazioni di ogni layer all’interno della rete neurale, anziché normalizzare gli input o gli output della rete nel loro insieme. Questa normalizzazione mitiga il problema dello spostamento covariante interno, che si riferisce al cambiamento nella distribuzione delle attivazioni della rete causato dalle modifiche dei parametri della rete.
- GPT 2 è anche alimentato da algoritmi di campionamento superiori rispetto a GPT 1. I miglioramenti chiave includono:
- Campionamento Top – p: Vengono considerati solo i token con una massa probabile cumulativa superiore a una certa soglia durante il campionamento. Ciò evita il campionamento da token a bassa probabilità, risultando in una generazione di testo più diversa e coerente.
- Scalatura della temperatura dei logit (cioè l’output grezzo della rete neurale prima di Softmax), controlla il livello di casualità nel testo generato. Temperature più basse producono un testo più conservativo e prevedibile, mentre temperature più alte producono un testo più creativo ed imprevedibile.
- Opzione di campionamento non condizionato (campionamento casuale), che consente agli utenti di esplorare le capacità generative del modello e può produrre risultati ingegnosi.
GPT-3
| Fonte dati di addestramento | Dimensione dei dati di addestramento |
| Common Crawl, BookCorpus, Wikipedia, Books, Articles, e altri ancora | oltre 570 GB di dati testuali |
Il Modello GPT-3 è un’evoluzione del Modello GPT-2, superandolo in diversi aspetti. È stato addestrato su un corpus di dati testuali significativamente più grande e presenta un massimo di 175 miliardi di parametri.
Oltre alla sua maggiore dimensione, GPT-3 ha introdotto diversi miglioramenti degni di nota:
- GShard ( parallellismo del modello gigante sharded): consente di suddividere il modello su più acceleratori. Ciò facilita l’addestramento e l’inferenza paralleli, in particolare per i grandi modelli linguistici con miliardi di parametri.
- Le capacità di apprendimento a zero-shot facilitano GPT-3 a mostrare la capacità di svolgere compiti per i quali non era stato esplicitamente addestrato. Ciò significa che potrebbe generare testo in risposta a prompt nuovi sfruttando la sua comprensione generale del linguaggio e del compito assegnato.
- Le capacità di apprendimento a pochi-shot alimentano GPT-3 per adattarsi rapidamente a nuovi compiti e domini con un addestramento minimo. Dimostra una notevole capacità di apprendere da un piccolo numero di esempi.
- Supporto multilingue: GPT-3 è in grado di generare testo in circa 30 lingue, tra cui inglese, cinese, francese, tedesco e arabo. Questo ampio supporto multilingue lo rende un modello linguistico altamente versatile per diverse applicazioni.
- Miglioramento del campionamento: GPT-3 utilizza un algoritmo di campionamento migliorato che include la possibilità di regolare la casualità nel testo generato, simile a GPT-2. Inoltre, introduce l’opzione di campionamento “prompted”, consentendo la generazione di testo basata su prompt o contesti specificati dall’utente.
GPT-3.5
| Fonte dati di addestramento | Dimensione dei dati di addestramento |
| Common Crawl, BookCorpus, Wikipedia, Books, Articles, e altri ancora | > 570 GB |
Similmente ai suoi predecessori, i modelli della serie GPT-3.5 sono derivati dai modelli GPT-3. Tuttavia, la caratteristica distintiva dei modelli GPT-3.5 risiede nella loro aderenza a politiche specifiche basate su valori umani, incorporate utilizzando una tecnica chiamata Reinforcement Learning with Human Feedback (RLHF). L’obiettivo principale era allineare i modelli più strettamente con le intenzioni dell’utente, mitigare la tossicità e dare la priorità alla veridicità nella loro produzione di output. Questa evoluzione rappresenta uno sforzo consapevole per migliorare l’uso etico e responsabile dei modelli linguistici al fine di fornire un’esperienza utente più sicura e affidabile.
Miglioramenti rispetto a GPT-3:
OpenAI ha utilizzato il Reinforcement Learning dal feedback umano per perfezionare GPT-3 e consentirgli di seguire un’ampia gamma di istruzioni. La tecnica RLHF prevede l’addestramento del modello utilizzando i principi del reinforcement learning, in cui il modello riceve ricompense o penalità in base alla qualità e all’allineamento dei suoi output generati con i valutatori umani. Integrando questo feedback nel processo di formazione, il modello acquisisce la capacità di imparare dagli errori e migliorare le sue prestazioni, producendo infine output di testo più naturali e coinvolgenti.
GPT 4
GPT-4 rappresenta l’ultimo modello della serie GPT che introduce capacità multimodali che consentono di elaborare sia input di testo che di immagini durante la generazione di output di testo. Può gestire vari formati di immagini, tra cui documenti con testo, fotografie, diagrammi, grafici, schemi e screenshot.
Sebbene OpenAI non abbia divulgato dettagli tecnici come la dimensione del modello, l’architettura, la metodologia di formazione o i pesi del modello per GPT-4, alcune stime suggeriscono che comprenda quasi 1 trilione di parametri. Il modello di base di GPT-4 segue un obiettivo di formazione simile ai modelli GPT precedenti, mirando a prevedere la parola successiva data una sequenza di parole. Il processo di formazione ha comportato l’utilizzo di un enorme corpus di dati pubblicamente disponibili su internet e di dati con licenza.
GPT-4 ha mostrato prestazioni superiori rispetto a GPT-3.5 nelle valutazioni di factuality avversaria interne di OpenAI e nei benchmark pubblici come TruthfulQA. Le tecniche RLHF utilizzate in GPT-3.5 sono state anche incorporate in GPT-4. OpenAI cerca attivamente di migliorare GPT-4 in base ai feedback ricevuti da ChatGPT e altre fonti.
Confronto delle prestazioni dei modelli GPT per le attività di modellizzazione standard
Punteggi di GPT-1, GPT-2 e GPT-3 in attività di modellizzazione NLP standard LAMBDA, GLUE e SQuAD.
| Modello | GLUE | LAMBADA | SQuAD F1 | SQuAD Exact Match |
| GPT-1 | 68,4 | 48,4 | 82,0 | 74,6 |
| GPT-2 | 84,6 | 60,1 | 89,5 | 83,0 |
| GPT-3 | 93,2 | 69,6 | 92,4 | 88,8 |
| GPT-3.5 | 93,5 | 79,3 | 92,4 | 88,8 |
| GPT-4 | 94,2 | 82,4 | 93,6 | 90,4 |
Tutti i numeri sono in percentuale. || fonte – BARD
Questa tabella dimostra il miglioramento costante dei risultati, che può essere attribuito agli miglioramenti sopracitati.
GPT-3.5 e GPT-4 sono testati sui nuovi benchmark e sui test standard.
I nuovi modelli GPT (3.5 e 4) sono testati sulle attività che richiedono ragionamento e conoscenza del dominio. I modelli sono stati testati su numerosi esami noti per essere impegnativi. Uno di questi esami per cui GPT-3 (ada, babbage, curie, davinci), GPT-3.5, ChatGPT e GPT-4 sono comparati è l’esame MBE. Dal grafico possiamo vedere un miglioramento continuo del punteggio, con GPT-4 che batte persino il punteggio medio degli studenti.
La figura 1 illustra il confronto percentuale dei voti ottenuti in MBE* dai diversi modelli GPT: 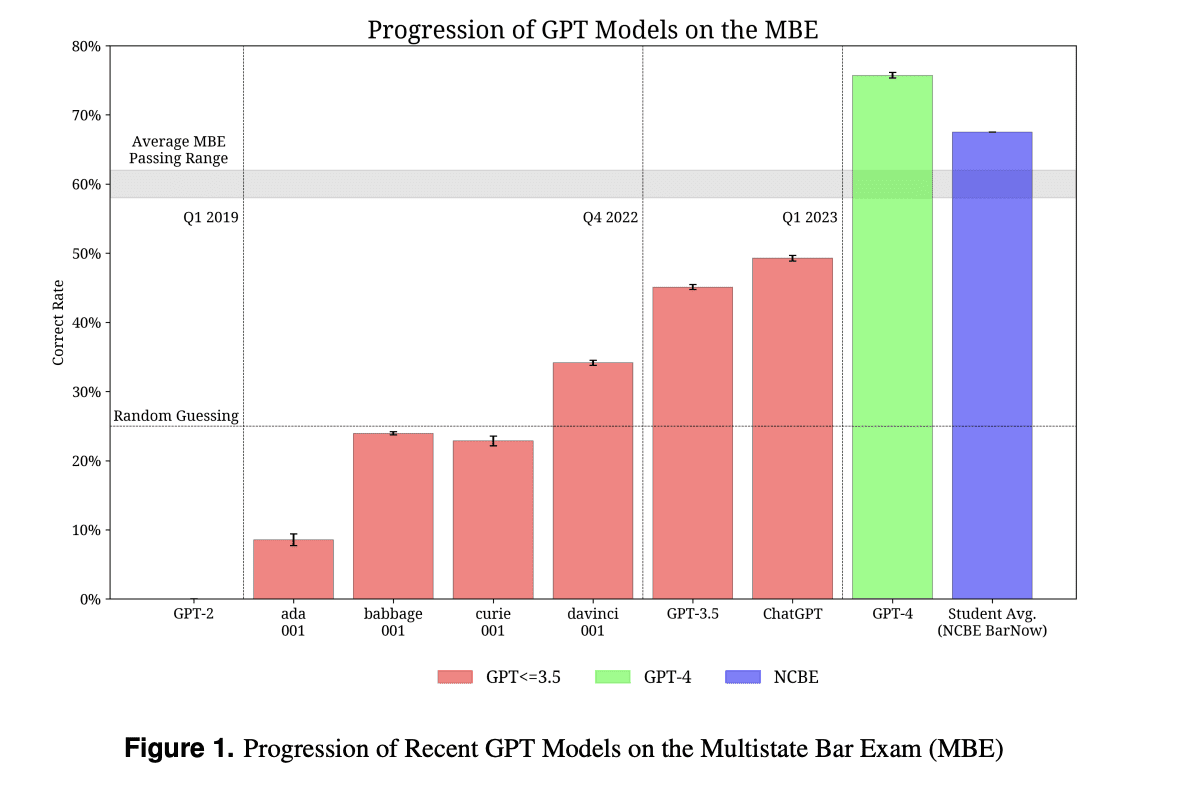
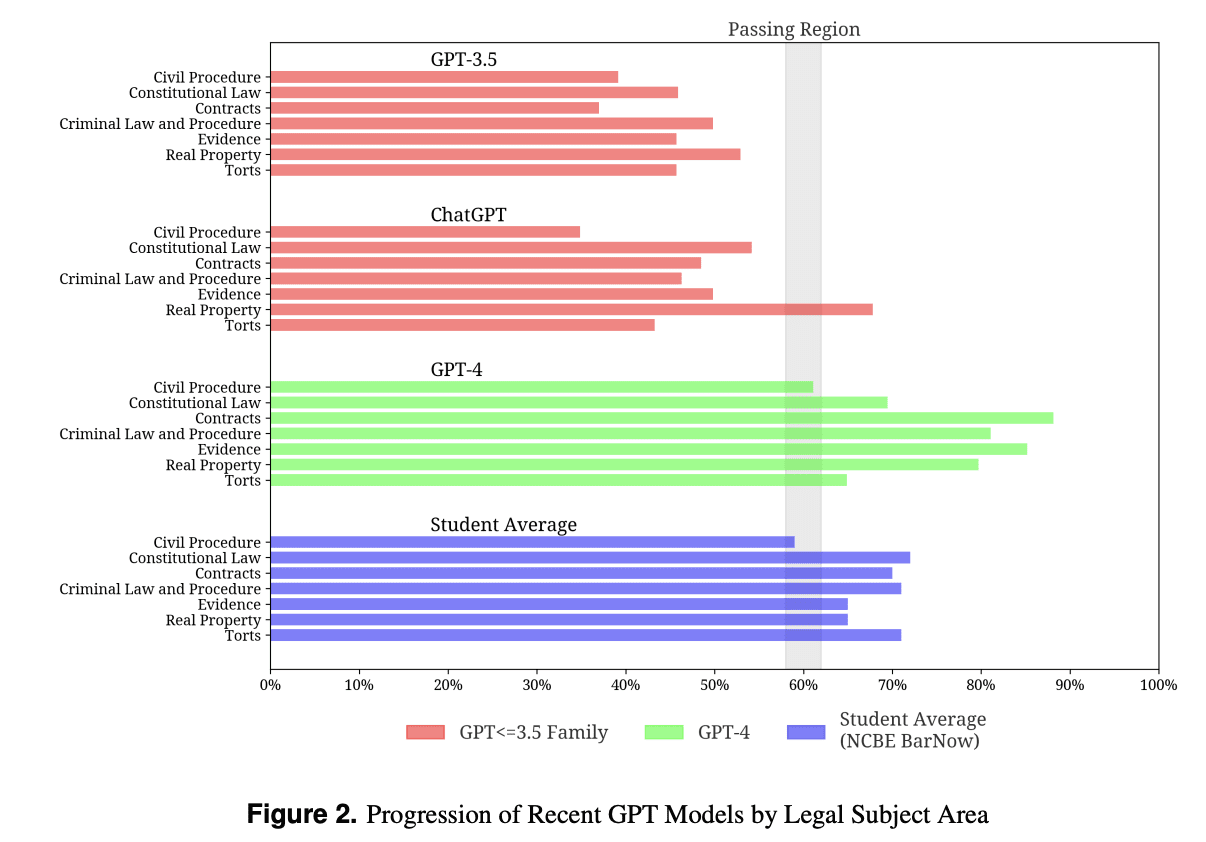
I grafici sottostanti evidenziano anche il progresso dei modelli e nuovamente battono i punteggi medi degli studenti per diverse aree di materia giuridica.
Conclusione
Con la crescita dei modelli di linguaggio basati su trasformatori (LLM), il campo dell’elaborazione del linguaggio naturale sta subendo una rapida evoluzione. Tra i vari modelli di linguaggio costruiti su questa architettura, i modelli GPT sono emersi eccezionali in termini di output e performance. OpenAI, l’organizzazione dietro GPT, ha costantemente migliorato il modello su molteplici fronti fin dalla pubblicazione del primo modello.
Nel corso di cinque anni, la dimensione del modello è cresciuta significativamente, espandendosi circa 8.500 volte da GPT-1 a GPT-4. Questo notevole progresso può essere attribuito al miglioramento continuo in aree come la dimensione dei dati di addestramento, la qualità dei dati, le fonti di dati, le tecniche di addestramento e il numero di parametri. Questi fattori hanno svolto un ruolo fondamentale nel consentire ai modelli di offrire prestazioni eccezionali in una vasta gamma di attività.
- Ankit Mehra è un data scientist senior presso Sigmoid. Si specializza in soluzioni di dati basate su analytics e ML.
- Malhar Yadav è un data scientist associato presso Sigmoid e un appassionato di codifica e ML.
- Bhaskar Ammu è un lead data scientist senior presso Sigmoid. Si specializza nella progettazione di soluzioni di data science per i clienti, nella costruzione di architetture di database e nella gestione di progetti e team.