5 Migliori LLM Open Source
5 migliori LLM open source
Nel mondo in rapida evoluzione dell’intelligenza artificiale (AI), i Large Language Models (LLM) sono emersi come una pietra angolare, guidando le innovazioni e plasmando il modo in cui interagiamo con la tecnologia.
Man mano che questi modelli diventano sempre più sofisticati, c’è una crescente enfasi sulla democratizzazione dell’accesso ad essi. I modelli open-source, in particolare, stanno svolgendo un ruolo fondamentale in questa democratizzazione, offrendo ai ricercatori, agli sviluppatori e agli appassionati l’opportunità di approfondirne le sfumature, ottimizzarli per compiti specifici o addirittura costruire su di essi.
In questo blog, esploreremo alcuni dei migliori LLM open-source che stanno facendo scalpore nella comunità dell’AI, ognuno portando al tavolo i suoi punti di forza e le sue capacità uniche.
1. Llama 2
- Una guida per migliorare le prestazioni di gioco della tua macchina virtuale
- L’IA generativa prende il centro della scena alla conferenza Ai4 del 2023
- Nuova Task Force per lo studio dell’IA generativa istituita dal Pentagono
Llama 2 di Meta è una rivoluzionaria aggiunta alla loro linea di modelli di intelligenza artificiale. Non si tratta solo di un altro modello; è progettato per alimentare una serie di applicazioni all’avanguardia. I dati di addestramento di Llama 2 sono vasti e vari, rendendolo un significativo avanzamento rispetto al suo predecessore. Questa diversità nell’addestramento assicura che Llama 2 non sia solo un miglioramento incrementale, ma un passo monumentale verso il futuro delle interazioni basate sull’IA.
La collaborazione tra Meta e Microsoft ha ampliato gli orizzonti per Llama 2. Il modello open-source è ora supportato su piattaforme come Azure e Windows, con l’obiettivo di fornire agli sviluppatori e alle organizzazioni gli strumenti per creare esperienze generative basate sull’IA. Questa partnership sottolinea la dedizione di entrambe le aziende nel rendere l’IA più accessibile e aperta a tutti.
Llama 2 non è solo un successore del modello originale Llama; rappresenta una svolta nel campo dei chatbot. Mentre il primo modello Llama era rivoluzionario nella generazione di testo e codice, la sua disponibilità era limitata per prevenire abusi. Llama 2, d’altra parte, è destinato a raggiungere un pubblico più ampio. È ottimizzato per piattaforme come AWS, Azure e la piattaforma di hosting dei modelli di intelligenza artificiale di Hugging Face. Inoltre, con la collaborazione di Meta con Microsoft, Llama 2 è destinato a fare la differenza non solo su Windows, ma anche su dispositivi alimentati dal sistema su chip Snapdragon di Qualcomm.
La sicurezza è al centro del design di Llama 2. Riconoscendo le sfide affrontate dai modelli di linguaggio di grandi dimensioni precedenti come GPT, che a volte producevano contenuti fuorvianti o dannosi, Meta ha adottato misure estensive per garantire l’affidabilità di Llama 2. Il modello è stato sottoposto a un addestramento rigoroso per ridurre al minimo le “allucinazioni”, le informazioni errate e i pregiudizi.
Principali caratteristiche di Llama 2:
- Dati di addestramento diversificati: I dati di addestramento di Llama 2 sono estesi e vari, garantendo una comprensione e una performance complete.
- Collaborazione con Microsoft: Llama 2 è supportato su piattaforme come Azure e Windows, ampliando il suo ambito di applicazione.
- Disponibilità aperta: A differenza del suo predecessore, Llama 2 è disponibile per un pubblico più ampio, pronto per essere ottimizzato su piattaforme multiple.
- Design incentrato sulla sicurezza: Meta ha enfatizzato la sicurezza, garantendo che Llama 2 produca risultati accurati e affidabili riducendo al minimo le uscite dannose.
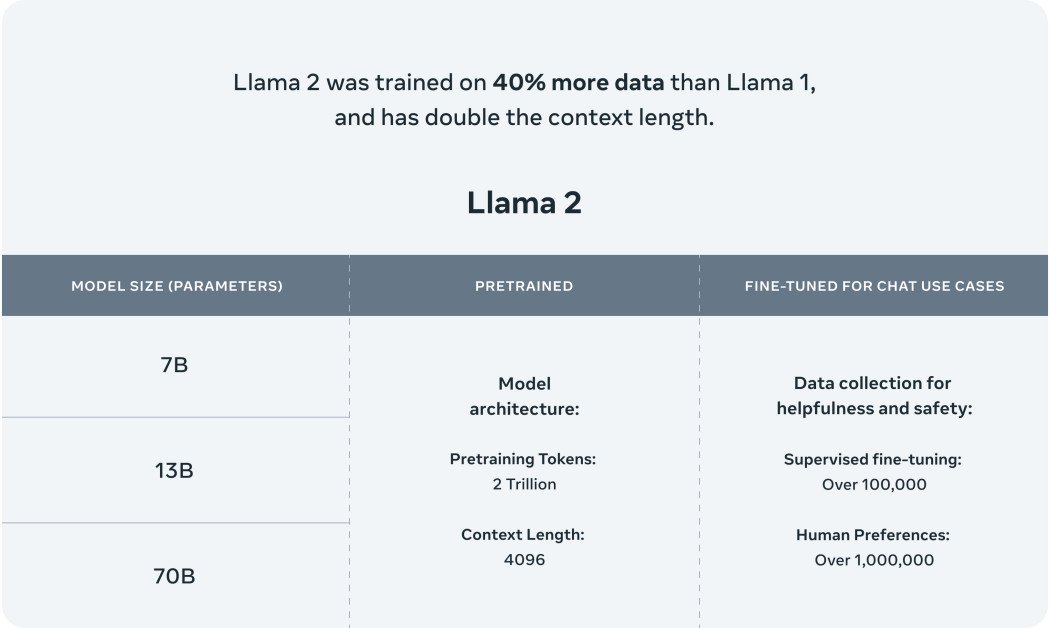
- Versioni ottimizzate: Llama 2 è disponibile in due versioni principali – Llama 2 e Llama 2-Chat, quest’ultima appositamente progettata per conversazioni bidirezionali. Queste versioni variano in complessità da 7 miliardi a 70 miliardi di parametri.
- Addestramento migliorato: Llama 2 è stato addestrato su due milioni di token, un aumento significativo rispetto all’originale Llama con 1,4 trilioni di token.
2. Claude 2

Il più recente modello di intelligenza artificiale di Anthropic, Claude 2, non è solo un aggiornamento, ma rappresenta un significativo avanzamento nelle capacità dei modelli di intelligenza artificiale. Con le sue metriche di performance migliorate, Claude 2 è progettato per fornire agli utenti risposte estese e coerenti. L’accessibilità di questo modello è ampia, disponibile sia tramite un’API che tramite il suo sito web beta dedicato. I feedback degli utenti indicano che le interazioni con Claude sono intuitive, con il modello che offre spiegazioni dettagliate e dimostra una capacità di memoria estesa.
In termini di capacità accademiche e di ragionamento, Claude 2 ha ottenuto risultati notevoli. Il modello ha raggiunto un punteggio del 76,5% nella sezione a scelta multipla dell’esame di avvocatura, migliorando rispetto al 73,0% ottenuto da Claude 1.3. Quando confrontato con studenti universitari che si preparano per programmi di laurea, Claude 2 ha ottenuto una performance superiore al 90° percentile negli esami di lettura e scrittura GRE, indicando la sua competenza nella comprensione e generazione di contenuti complessi.
La versatilità di Claude 2 è un’altra caratteristica degna di nota. Il modello può elaborare input fino a 100.000 token, consentendo di esaminare documenti estesi che vanno dai manuali tecnici ai libri completi. Inoltre, Claude 2 ha la capacità di produrre documenti estesi, dalle comunicazioni ufficiali alle narrazioni dettagliate, in modo fluido. Le capacità di codifica del modello sono state anche potenziate, con Claude 2 che ha ottenuto un punteggio del 71,2% nel Codex HumanEval, una valutazione di codifica Python, e dell’88,0% nel GSM8k, una collezione di sfide matematiche per la scuola primaria.
La sicurezza rimane una preoccupazione primaria per Anthropic. Gli sforzi sono stati concentrati per garantire che Claude 2 sia meno suscettibile a generare contenuti potenzialmente dannosi o inappropriati. Attraverso valutazioni interne meticolose e l’applicazione di metodologie avanzate di sicurezza, Claude 2 ha dimostrato un significativo miglioramento nella produzione di risposte benigna rispetto al suo predecessore.
Claude 2: Panoramica delle caratteristiche principali
- Miglioramento delle prestazioni: Claude 2 offre tempi di risposta più veloci e offre interazioni più dettagliate.
- Punti di accesso multipli: Il modello può essere accessibile tramite un’API o attraverso il suo sito web beta dedicato, claude.ai.
- Eccellenza accademica: Claude 2 ha mostrato risultati lodevoli nelle valutazioni accademiche, in particolare nei segmenti di lettura e scrittura del GRE.
- Capacità di input/output estese: Claude 2 può gestire input fino a 100.000 token ed è in grado di produrre documenti estesi in una singola sessione.
- Competenza avanzata di codifica: Le competenze di codifica del modello sono state affinate, come dimostrato dai suoi punteggi nelle valutazioni di codifica e matematica.
- Protocolli di sicurezza: Valutazioni rigorose e tecniche avanzate di sicurezza sono state adottate per garantire che Claude 2 produca output benigni.
- Piani di espansione: Mentre Claude 2 è attualmente accessibile negli Stati Uniti e nel Regno Unito, sono in previsione piani per espanderne la disponibilità a livello globale in un prossimo futuro.
3. MPT-7B

MosaicML Foundations ha dato un contributo significativo a questo settore con l’introduzione di MPT-7B, il loro ultimo LLM open-source. MPT-7B, acronimo di MosaicML Pretrained Transformer, è un modello di tipo GPT-style, basato solo sul decodificatore del transformer. Questo modello vanta diverse migliorie, tra cui implementazioni di layer ottimizzate per le prestazioni e cambiamenti architettonici che garantiscono una maggiore stabilità nell’addestramento.
Una caratteristica eccezionale di MPT-7B è il suo addestramento su un dataset esteso composto da 1 trilione di token di testo e codice. Questo rigoroso addestramento è stato eseguito sulla piattaforma MosaicML in un arco di tempo di 9,5 giorni.
La natura open-source di MPT-7B lo rende uno strumento prezioso per le applicazioni commerciali. Ha il potenziale per avere un impatto significativo sull’analisi predittiva e sui processi decisionali delle aziende e delle organizzazioni.
Oltre al modello base, MosaicML Foundations sta anche rilasciando modelli specializzati su misura per compiti specifici, come MPT-7B-Instruct per l’inseguimento di istruzioni in formato breve, MPT-7B-Chat per la generazione di dialoghi e MPT-7B-StoryWriter-65k+ per la creazione di storie in formato lungo.
Il percorso di sviluppo di MPT-7B è stato completo, con il team di MosaicML che ha gestito tutte le fasi, dalla preparazione dei dati alla distribuzione, in poche settimane. I dati sono stati raccolti da diverse repository e il team ha utilizzato strumenti come GPT-NeoX di EleutherAI e il tokenizer 20B per garantire una miscela di addestramento varia e completa.
Panoramica delle caratteristiche principali di MPT-7B:
- Licenza commerciale: MPT-7B è autorizzato per l’uso commerciale, rendendolo un asset prezioso per le aziende.
- Dataset di addestramento esteso: Il modello vanta un addestramento su un vasto dataset di 1 trilione di token.
- Gestione di input lunghi: MPT-7B è progettato per elaborare input estremamente lunghi senza compromessi.
- Velocità ed efficienza: Il modello è ottimizzato per un addestramento e un’elaborazione rapidi, garantendo risultati tempestivi.
- Codice open-source: MPT-7B è fornito con un codice di addestramento open-source efficiente, promuovendo la trasparenza e la facilità d’uso.
- Eccellenza comparativa: MPT-7B ha dimostrato superiorità rispetto ad altri modelli open-source nella gamma 7B-20B, con una qualità che si avvicina a quella di LLaMA-7B.
4. Falcon

Falcon LLM, è un modello che è rapidamente salito in cima all’elenco dei LLM. Falcon LLM, nello specifico Falcon-40B, è un LLM fondamentale dotato di 40 miliardi di parametri ed è stato addestrato su un impressionante trilione di token. Funziona come un modello autoregressivo decoder-only, il che significa essenzialmente che predice il token successivo in una sequenza basandosi sui token precedenti. Questa architettura ricorda il modello GPT. Notevolmente, l’architettura di Falcon ha dimostrato una performance superiore a GPT-3, raggiungendo questo risultato con solo il 75% del budget di calcolo dell’addestramento e richiedendo un calcolo significativamente inferiore durante l’inferenza.
Il team presso il Technology Innovation Institute ha posto una forte enfasi sulla qualità dei dati durante lo sviluppo di Falcon. Riconoscendo la sensibilità dei LLM alla qualità dei dati di addestramento, hanno costruito un flusso di dati che si è esteso a decine di migliaia di CPU. Questo ha permesso un rapido processamento e l’estrazione di contenuti di alta qualità dal web, ottenuti attraverso processi di filtraggio e deduplicazione estensivi.
Oltre a Falcon-40B, TII ha anche introdotto altre versioni, tra cui Falcon-7B, che possiede 7 miliardi di parametri ed è stato addestrato su 1.500 miliardi di token. Ci sono anche modelli specializzati come Falcon-40B-Instruct e Falcon-7B-Instruct, adattati per compiti specifici.
L’addestramento di Falcon-40B è stato un processo esteso. Il modello è stato addestrato sul dataset RefinedWeb, un massiccio dataset in lingua inglese costruito da TII. Questo dataset è stato costruito su CommonCrawl ed è stato sottoposto a un rigoroso processo di filtraggio per garantirne la qualità. Una volta che il modello è stato preparato, è stato convalidato su diversi benchmark open-source, tra cui EAI Harness, HELM e BigBench.
Panoramica delle caratteristiche chiave di Falcon LLM:
- Parametri estesi: Falcon-40B è dotato di 40 miliardi di parametri, garantendo un apprendimento e una performance completi.
- Modello autoregressivo decoder-only: Questa architettura consente a Falcon di predire i token successivi basandosi su quelli precedenti, simile al modello GPT.
- Performance superiori: Falcon supera GPT-3 utilizzando solo il 75% del budget di calcolo dell’addestramento.
- Flusso di dati di alta qualità: Il flusso di dati di TII garantisce l’estrazione di contenuti di alta qualità dal web, fondamentale per l’addestramento del modello.
- Varie versioni del modello: Oltre a Falcon-40B, TII offre Falcon-7B e modelli specializzati come Falcon-40B-Instruct e Falcon-7B-Instruct.
- Disponibilità open-source: Falcon LLM è stato reso open-source, promuovendo l’accessibilità e l’inclusività nel campo dell’AI.
Vicuna-13B

LMSYS ORG ha fatto un segno significativo nel campo dei LLM open-source con l’introduzione di Vicuna-13B. Questo chatbot open-source è stato meticolosamente addestrato attraverso il fine-tuning di LLaMA su conversazioni condivise dagli utenti provenienti da ShareGPT. Valutazioni preliminari, con GPT-4 come giudice, indicano che Vicuna-13B raggiunge una qualità superiore al 90% rispetto a modelli rinomati come OpenAI ChatGPT e Google Bard.
In modo impressionante, Vicuna-13B supera altri modelli noti come LLaMA e Stanford Alpaca in oltre il 90% dei casi. L’intero processo di addestramento per Vicuna-13B è stato eseguito a un costo approssimativo di $300. Per coloro interessati a esplorarne le capacità, il codice, i pesi e una demo online sono stati resi pubblicamente disponibili per scopi non commerciali.
Il modello Vicuna-13B è stato sintonizzato con 70.000 conversazioni condivise dagli utenti ChatGPT, consentendogli di generare risposte più dettagliate e ben strutturate. La qualità di queste risposte è paragonabile a quella di ChatGPT. Valutare i chatbot, tuttavia, è un compito complesso. Con gli avanzamenti di GPT-4, c’è una crescente curiosità sul suo potenziale di servire come framework di valutazione automatica per la generazione di benchmark e valutazioni delle performance. I risultati preliminari suggeriscono che GPT-4 possa produrre classifiche coerenti e valutazioni dettagliate nel confronto delle risposte dei chatbot. Valutazioni preliminari basate su GPT-4 mostrano che Vicuna raggiunge una capacità del 90% rispetto a modelli come Bard/ChatGPT.
Panoramica delle caratteristiche chiave di Vicuna-13B:
- Natura open-source: Vicuna-13B è disponibile per l’accesso pubblico, promuovendo la trasparenza e la partecipazione della comunità.
- Dati di allenamento estesi: Il modello è stato addestrato su 70.000 conversazioni condivise dagli utenti, garantendo una comprensione completa di interazioni diverse.
- Prestazioni competitive: Le prestazioni di Vicuna-13B sono all’altezza di leader del settore come ChatGPT e Google Bard.
- Allenamento a basso costo: L’intero processo di addestramento per Vicuna-13B è stato eseguito a un costo ridotto di circa $300.
- Perfezionamento su LLaMA: Il modello è stato perfezionato su LLaMA, garantendo prestazioni migliorate e qualità della risposta.
- Disponibilità di demo online: È disponibile una demo online interattiva per consentire agli utenti di testare e sperimentare le capacità di Vicuna-13B.
Il vasto e in espansione campo dei grandi modelli di linguaggio
Il campo dei grandi modelli di linguaggio è vasto e in continua espansione, con ogni nuovo modello che spinge i limiti di ciò che è possibile. La natura open-source dei LLM discussi in questo blog non solo mostra lo spirito collaborativo della comunità dell’intelligenza artificiale, ma getta anche le basi per future innovazioni.
Questi modelli, dalle impressionanti capacità di chatbot di Vicuna alle superiori metriche di prestazione di Falcon, rappresentano l’apice della tecnologia dei LLM attuale. Mentre continuiamo a assistere a rapidi progressi in questo campo, è evidente che i modelli open-source svolgeranno un ruolo cruciale nel plasmare il futuro dell’intelligenza artificiale.
Sia che tu sia un ricercatore esperto, un appassionato di intelligenza artificiale in erba o semplicemente curioso delle potenzialità di questi modelli, non c’è momento migliore per immergersi ed esplorare le vaste possibilità che offrono.