Dieci anni di Intelligenza Artificiale in rassegna
10 years of Artificial Intelligence reviewed
Dalla classificazione delle immagini alla terapia dei chatbot.
Il decennio scorso è stato un viaggio emozionante e pieno di eventi per il campo dell’intelligenza artificiale (AI). Le esplorazioni modeste del potenziale del deep learning si sono trasformate in una proliferazione esplosiva di un campo che ora include tutto, dai sistemi di raccomandazione nell’e-commerce alla rilevazione degli oggetti per i veicoli autonomi e ai modelli generativi che possono creare tutto, dalle immagini realistiche al testo coerente.
In questo articolo, faremo un viaggio nella memoria e rivisiteremo alcune delle svolte chiave che ci hanno portato dove siamo oggi. Che tu sia un esperto praticante di AI o semplicemente interessato agli ultimi sviluppi nel campo, questo articolo ti fornirà una panoramica completa del notevole progresso che ha portato l’AI a diventare un nome familiare.
- Iniziare con ReactPy
- Crea una Dashboard di Analisi del Rapporto delle Serie Temporali
- Gli effetti di ChatGPT nelle scuole e perché sta venendo vietato
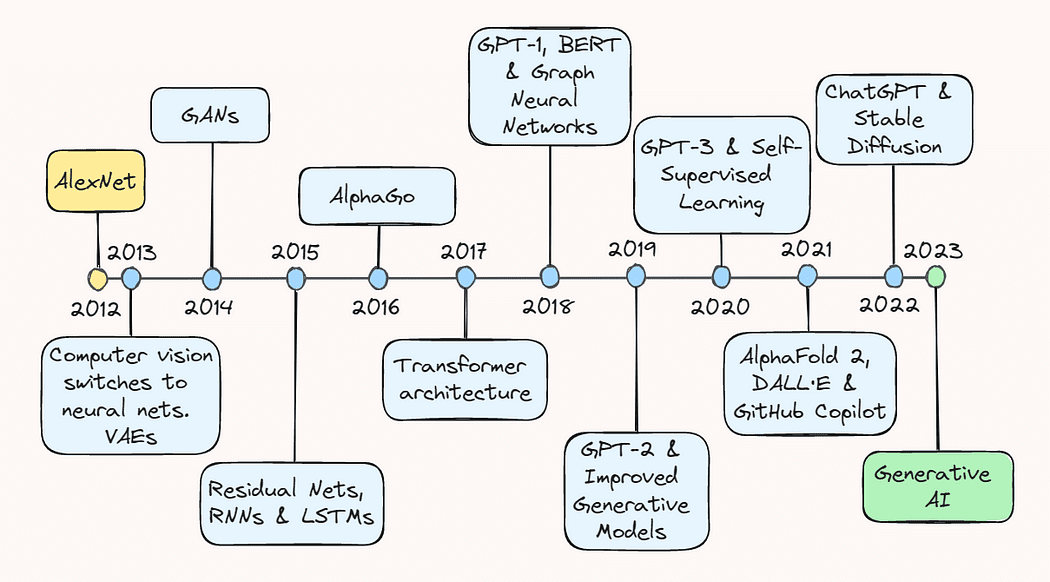
2013: AlexNet e Variational Autoencoders
L’anno 2013 è ampiamente considerato come il “coming-of-age” del deep learning, avviato da importanti progressi nella visione artificiale. Secondo un’intervista recente di Geoffrey Hinton, entro il 2013 “praticamente tutta la ricerca sulla visione artificiale era passata alle reti neurali”. Questo boom è stato principalmente alimentato da una svolta piuttosto sorprendente nella riconoscimento delle immagini un anno prima.
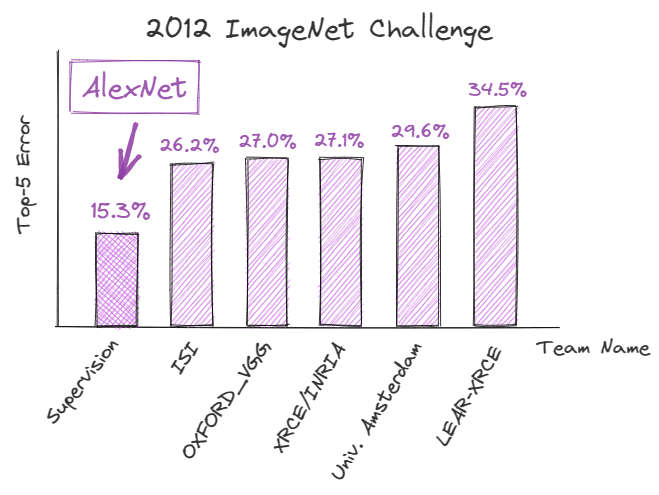
Nel settembre 2012, AlexNet, una rete neurale convoluzionale (CNN) profonda, ha ottenuto una prestazione record nella ImageNet Large Scale Visual Recognition Challenge (ILSVRC), dimostrando il potenziale del deep learning per le attività di riconoscimento delle immagini. Ha ottenuto un errore del top-5 del 15,3%, che era inferiore del 10,9% rispetto al suo concorrente più vicino.
Il miglioramento tecnico dietro questo successo è stato fondamentale per la futura traiettoria dell’AI e ha cambiato radicalmente il modo in cui il deep learning è stato percepito.
Innanzitutto, gli autori hanno applicato una CNN profonda composta da cinque strati convoluzionali e tre strati lineari completamente connessi – un design architettonico respinto da molti come impraticabile all’epoca. Inoltre, a causa del grande numero di parametri prodotti dalla profondità della rete, l’addestramento è stato effettuato in parallelo su due unità di elaborazione grafica (GPU), dimostrando la capacità di accelerare significativamente l’addestramento su grandi set di dati. Il tempo di addestramento è stato ulteriormente ridotto sostituendo le funzioni di attivazione tradizionali, come sigmoid e tanh, con l’unità lineare rettificata (ReLU) più efficiente.
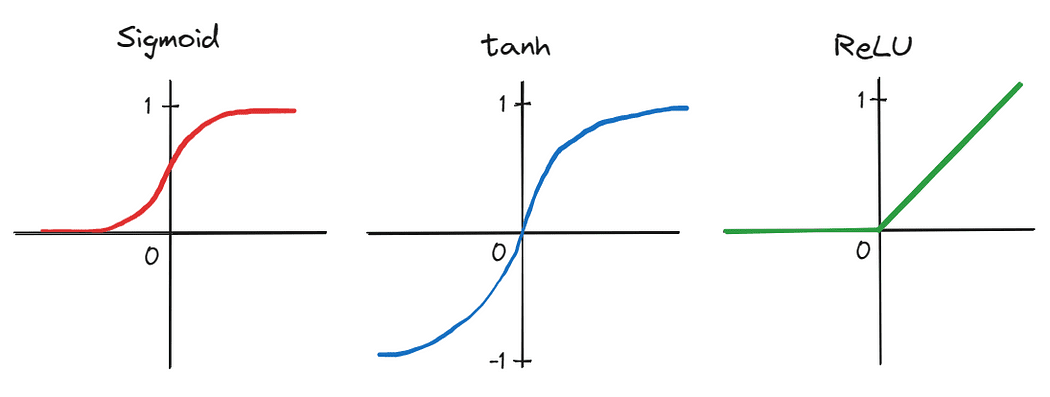
Questi progressi che, collettivamente, hanno portato al successo di AlexNet, hanno segnato un punto di svolta nella storia dell’AI e hanno suscitato un’impennata di interesse nel deep learning sia tra gli accademici che nella comunità tecnologica. Di conseguenza, il 2013 è considerato da molti come il punto di inflessione dopo il quale il deep learning ha veramente iniziato a decollare.
Ciò che è accaduto anche nel 2013, sebbene un po’ soffocato dal rumore di AlexNet, è stato lo sviluppo di autoencoder variazionali, o VAE – modelli generativi che possono imparare a rappresentare e generare dati come immagini e suoni. Funzionano imparando una rappresentazione compressa dei dati di input in uno spazio di dimensioni inferiori, noto come spazio latente. Ciò consente loro di generare nuovi dati campionando da questo spazio latente appreso. I VAE, in seguito, si sono rivelati utili per aprire nuove strade per la modellizzazione generativa e la generazione di dati, con applicazioni in campi come l’arte, il design e i giochi.
2014: Generative Adversarial Networks
L’anno successivo, nel giugno 2014, il campo del deep learning ha assistito a un altro serio avanzamento con l’introduzione delle reti generative avversarie, o GAN, da parte di Ian Goodfellow e colleghi.
Le GAN sono un tipo di rete neurale in grado di generare nuovi campioni di dati simili a un set di addestramento. Fondamentalmente, due reti sono addestrate contemporaneamente: (1) una rete generatrice genera campioni falsi o sintetici e (2) una rete discriminante valuta la loro autenticità. Questo addestramento viene eseguito in un ambiente simile a un gioco, con il generatore che cerca di creare campioni che ingannano il discriminante e il discriminante che cerca di chiamare correttamente i campioni falsi.
In quel momento, le GAN rappresentavano uno strumento potente e nuovo per la generazione di dati, utilizzato non solo per generare immagini e video, ma anche musica e arte. Hanno anche contribuito all’avanzamento dell’apprendimento non supervisionato, un dominio largamente considerato sottosviluppato e difficile, dimostrando la possibilità di generare campioni di dati di alta qualità senza affidarsi a etichette esplicite.
2015: ResNets e svolte NLP
Nel 2015, il campo dell’AI ha fatto notevoli progressi sia nella visione artificiale che nell’elaborazione del linguaggio naturale, o NLP.
Kaiming He e i suoi colleghi hanno pubblicato un articolo intitolato “Deep Residual Learning for Image Recognition”, in cui hanno introdotto il concetto di reti neurali residue, o ResNets – architetture che consentono al flusso di informazioni di fluire più facilmente attraverso la rete aggiungendo scorciatoie. A differenza di una normale rete neurale, in cui ciascuno strato prende l’output dello strato precedente come input, in una ResNet vengono aggiunte connessioni residue aggiuntive che saltano uno o più strati e si connettono direttamente a strati più profondi nella rete.
Ciò ha permesso alle ResNets di risolvere il problema della scomparsa dei gradienti, consentendo la formazione di reti neurali molto più profonde di quanto si pensasse possibile in quel momento. Ciò, a sua volta, ha portato a miglioramenti significativi nelle attività di classificazione delle immagini e di riconoscimento degli oggetti.
Nello stesso periodo, i ricercatori hanno compiuto notevoli progressi nello sviluppo di reti neurali ricorrenti ( RNNs ) e modelli di memoria a breve e lungo termine ( LSTM ). Nonostante esistessero già dagli anni ’90, questi modelli hanno iniziato a suscitare interesse intorno al 2015, principalmente a causa di fattori come (1) la disponibilità di set di dati più ampi e diversi per la formazione, (2) miglioramenti nella potenza computazionale e nell’hardware, che hanno consentito la formazione di modelli più profondi e complessi, e (3) modifiche apportate lungo la strada, come meccanismi di gating più sofisticati.
Ciò ha reso possibile per i modelli di lingua comprendere meglio il contesto e il significato del testo, portando a notevoli miglioramenti in attività come la traduzione linguistica, la generazione di testo e l’analisi del sentiment. Il successo di RNNs e LSTMs in quel periodo ha aperto la strada allo sviluppo dei grandi modelli di lingua (LLMs) che vediamo oggi.
2016: AlphaGo
Dopo la sconfitta di Garry Kasparov da parte di Deep Blue di IBM nel 1997, un’altra sfida uomo vs. macchina ha fatto tremare il mondo dei giochi nel 2016: AlphaGo di Google ha sconfitto il campione mondiale di Go, Lee Sedol.

La sconfitta di Sedol ha segnato un altro importante traguardo nella traiettoria dell’avanzamento dell’AI: ha dimostrato che le macchine possono superare anche i giocatori umani più abili in un gioco che una volta era considerato troppo complesso per i computer. Utilizzando una combinazione di apprendimento profondo per rinforzo e ricerca dell’albero di Monte Carlo, AlphaGo analizza milioni di posizioni da giochi precedenti e valuta le migliori mosse possibili – una strategia che supera di gran lunga la decisione umana in questo contesto.
2017: Architettura Transformer e Modelli di Lingua
In modo discutibile, il 2017 è stato l’anno più cruciale che ha gettato le basi per le scoperte nell’AI generativa che stiamo assistendo oggi.
Nel dicembre 2017, Vaswani e i suoi colleghi hanno pubblicato l’articolo fondamentale “Attention is all you need”, che ha introdotto l’architettura Transformer che sfrutta il concetto di auto-attenzione per elaborare dati di input sequenziali. Ciò ha consentito una elaborazione più efficiente delle dipendenze a lungo raggio, che in precedenza erano una sfida per le architetture RNN tradizionali.

I Transformer sono composti da due componenti essenziali: encoder e decoder. L’encoder è responsabile della codifica dei dati di input, che, ad esempio, possono essere una sequenza di parole. Prende quindi la sequenza di input e applica più strati di auto-attenzione e reti neurali feed-forward per catturare le relazioni e le caratteristiche all’interno della frase e apprendere rappresentazioni significative.
In sostanza, l’auto-attenzione consente al modello di comprendere le relazioni tra diverse parole in una frase. A differenza dei modelli tradizionali, che elaborerebbero le parole in un ordine fisso, i Transformer esaminano effettivamente tutte le parole contemporaneamente. Assegnano punteggi di attenzione a ciascuna parola in base alla sua rilevanza per le altre parole nella frase.
Il decoder, d’altra parte, prende la rappresentazione codificata dall’encoder e produce una sequenza di output. In attività come la traduzione automatica o la generazione di testo, il decoder genera la sequenza tradotta in base all’input ricevuto dall’encoder. Similmente all’encoder, il decoder è composto da più strati di auto-attenzione e reti neurali feed-forward. Tuttavia, include un meccanismo di attenzione aggiuntivo che gli consente di concentrarsi sull’output dell’encoder. Ciò consente al decoder di prendere in considerazione le informazioni rilevanti dalla sequenza di input durante la generazione dell’output.
L’architettura Transformer è diventata da allora un componente chiave nello sviluppo di LLMs e ha portato a miglioramenti significativi in tutto il dominio del NLP, come la traduzione automatica, la modellizzazione del linguaggio e la risposta alle domande.
2018: GPT-1, BERT e le reti neurali a grafo
Pochi mesi dopo che Vaswani et al. pubblicarono il loro fondamentale articolo, la Generative Pretrained Transformer, o GPT-1 , fu introdotta da OpenAI nel giugno del 2018, che utilizzò l’architettura del transformer per catturare efficacemente le dipendenze a lungo raggio nel testo. GPT-1 fu uno dei primi modelli a dimostrare l’efficacia del pre-training non supervisionato seguito dalla messa a punto su specifiche attività di elaborazione del linguaggio naturale.
Sfruttando anche l’architettura del transformer ancora piuttosto nuova, Google, alla fine del 2018, rilasciò e condivise il proprio metodo di pre-training chiamato Bidirectional Encoder Representations from Transformers, o BERT . A differenza dei modelli precedenti che elaborano il testo in modo unidirezionale (compreso GPT-1), BERT considera il contesto di ogni parola in entrambe le direzioni contemporaneamente. Per illustrare questo, gli autori forniscono un esempio molto intuitivo:
…nella frase “Ho acceduto al conto bancario”, un modello contestuale unidirezionale rappresenterebbe “banca” sulla base di “Ho acceduto al”, ma non di “conto”. Tuttavia, BERT rappresenta “banca” utilizzando anche il contesto precedente e successivo – “Ho acceduto al…conto” – partendo dal fondo di una rete neurale profonda, rendendolo profondamente bidirezionale.
Il concetto di bidirezionalità fu così potente che portò BERT a superare i sistemi di elaborazione del linguaggio naturale all’avanguardia su una varietà di attività di benchmark.
Oltre a GPT-1 e BERT, le reti neurali a grafo, o GNN, fecero rumore quell’anno. Appartengono a una categoria di reti neurali appositamente progettate per lavorare con dati a grafo. GNN utilizza un algoritmo di passaggio di messaggi per propagare le informazioni attraverso i nodi e gli archi di un grafo. Ciò consente alla rete di apprendere la struttura e le relazioni dei dati in modo molto più intuitivo.
Questo lavoro ha permesso di estrarre conoscenze molto più profonde dai dati e, di conseguenza, ha ampliato la gamma di problemi a cui si poteva applicare il deep learning. Con le GNN, sono stati possibili progressi significativi in aree come l’analisi delle reti sociali, i sistemi di raccomandazione e la scoperta di farmaci.
2019: GPT-2 e miglioramento dei modelli generativi
L’anno 2019 ha segnato diversi notevoli progressi nei modelli generativi, in particolare l’introduzione di GPT-2 . Questo modello ha davvero lasciato i suoi concorrenti polverizzati raggiungendo prestazioni all’avanguardia in molte attività di elaborazione del linguaggio naturale e, inoltre, era in grado di generare testi altamente realistici, il che, in retrospettiva, ci ha dato un’idea di ciò che stava per arrivare in questo settore.
Altre migliorie in questo ambito includono il BigGAN di DeepMind, che ha generato immagini di alta qualità che erano quasi indistinguibili dalle immagini reali, e lo StyleGAN di NVIDIA, che ha consentito un controllo migliore sull’aspetto di quelle immagini generate.
Collettivamente, questi progressi in ciò che oggi è noto come intelligenza artificiale generativa hanno spinto ancora più avanti i confini di questo dominio e…
2020: GPT-3 e apprendimento auto-supervisionato
…non molto tempo dopo, è nato un altro modello, che è diventato un nome familiare anche al di fuori della comunità tecnologica: GPT-3 . Questo modello rappresentava un grande salto in avanti nella scala e nelle capacità delle LLM. Per mettere le cose in prospettiva, GPT-1 aveva solo 117 milioni di parametri. Quel numero è salito a 1,5 miliardi per GPT-2 e 175 miliardi per GPT-3.
Questa vasta quantità di spazio dei parametri consente a GPT-3 di generare testi notevolmente coerenti su una vasta gamma di stimoli e attività. Inoltre, ha dimostrato prestazioni impressionanti in una varietà di attività di elaborazione del linguaggio naturale, come il completamento del testo, la risposta alle domande e persino la scrittura creativa.
Inoltre, GPT-3 ha messo in evidenza ancora una volta il potenziale dell’uso dell’apprendimento auto-supervisionato, che consente ai modelli di essere addestrati su grandi quantità di dati non etichettati. Ciò ha il vantaggio che questi modelli possono acquisire una comprensione ampia del linguaggio senza la necessità di un addestramento estensivo specifico per una determinata attività, il che lo rende molto più economico.
Yann LeCun tweetta su un articolo del NYT sull’apprendimento auto-supervisionato.
2021: AlphaFold 2, DALL·E e GitHub Copilot
Dalla piegatura delle proteine alla generazione di immagini e all’assistenza alla codifica automatizzata, l’anno 2021 è stato un anno pieno di eventi grazie ai rilasci di AlphaFold 2, DALL·E e GitHub Copilot.
AlphaFold 2 è stato accolto come una soluzione attesa da tempo al problema della piegatura delle proteine, vecchio di decenni. I ricercatori di DeepMind hanno esteso l’architettura del transformer per creare blocchi evoformer, ovvero architetture che sfruttano strategie evolutive per l’ottimizzazione del modello, per costruire un modello in grado di prevedere la struttura tridimensionale di una proteina sulla base della sua sequenza di aminoacidi unidimensionale. Questa svolta ha un enorme potenziale per rivoluzionare aree come la scoperta di farmaci, la bioingegneria e la nostra comprensione dei sistemi biologici.
Anche OpenAI è tornata alla ribalta quest’anno con il rilascio di DALL·E. In sostanza, questo modello combina i concetti dei modelli di linguaggio di stile GPT e la generazione di immagini per consentire la creazione di immagini di alta qualità da descrizioni testuali.
Per illustrare la potenza di questo modello, considera l’immagine qui sotto, generata con il prompt “Dipinto ad olio di un mondo futuristico con auto volanti”.

Infine, GitHub ha rilasciato quello che sarebbe diventato l’amico degli sviluppatori: Copilot. Questo è stato realizzato in collaborazione con OpenAI, che ha fornito il modello di linguaggio sottostante, Codex, che è stato addestrato su un ampio corpus di codice disponibile pubblicamente e, a sua volta, ha imparato a comprendere e generare codice in vari linguaggi di programmazione. Gli sviluppatori possono utilizzare Copilot semplicemente fornendo un commento di codice che indica il problema che stanno cercando di risolvere e il modello suggerirà quindi il codice da implementare per la soluzione. Altre funzioni includono la capacità di descrivere il codice di input in linguaggio naturale e di tradurre il codice tra i linguaggi di programmazione.
2022: ChatGPT e Stable Diffusion
Lo sviluppo rapido dell’AI nell’ultimo decennio ha culminato in un’importante avanzamento: ChatGPT di OpenAI, un chatbot rilasciato nel novembre 2022. Lo strumento rappresenta un risultato di frontiera nell’NLP, in grado di generare risposte coerenti e contestualmente pertinenti a una vasta gamma di richieste e prompt. Inoltre, può intrattenere conversazioni, fornire spiegazioni, offrire suggerimenti creativi, assistere nella risoluzione di problemi, scrivere e spiegare il codice e persino simulare diverse personalità o stili di scrittura.

L’interfaccia semplice e intuitiva attraverso cui è possibile interagire con il bot ha anche stimolato un forte aumento dell’usabilità. In passato, erano principalmente la comunità tecnologica a giocare con le ultime invenzioni basate sull’AI. Tuttavia, in questi giorni, gli strumenti di intelligenza artificiale hanno penetrato quasi ogni dominio professionale, dagli ingegneri del software ai redattori, musicisti e pubblicitari. Molte aziende stanno inoltre utilizzando il modello per automatizzare servizi come il supporto clienti, la traduzione linguistica o la risposta a domande frequenti. In realtà, l’onda di automazione che stiamo vedendo ha riacceso alcune preoccupazioni e stimolato discussioni su quali lavori potrebbero essere a rischio di automazione.
Anche se ChatGPT ha acaparato gran parte del centro dell’attenzione nel 2022, è stata fatta anche una significativa avanzamento nella generazione di immagini. Stable diffusion, un modello di diffusione latente di testo in immagine in grado di generare immagini fotorealistiche da descrizioni testuali, è stato rilasciato da Stability AI.
Stable diffusion è un’estensione dei modelli di diffusione tradizionali, che funzionano iterativamente aggiungendo rumore alle immagini e poi invertendo il processo per recuperare i dati. È stato progettato per accelerare questo processo operando non direttamente sulle immagini di input, ma invece su una rappresentazione a bassa dimensionalità, o spazio latente, di esse. Inoltre, il processo di diffusione è modificato aggiungendo la descrizione testuale incorporata dal prompt dell’utente alla rete, consentendole di guidare il processo di generazione dell’immagine in ogni iterazione.
In generale, il rilascio di ChatGPT e Stable Diffusion nel 2022 ha evidenziato il potenziale dell’AI multimodale e generativa e ha suscitato un enorme aumento di sviluppo e investimento in questo settore.
2023: LLM e Chatbot
L’anno in corso è senza dubbio emerso come l’anno di LLM e chatbot. Sempre più modelli vengono sviluppati e rilasciati a un ritmo sempre crescente.
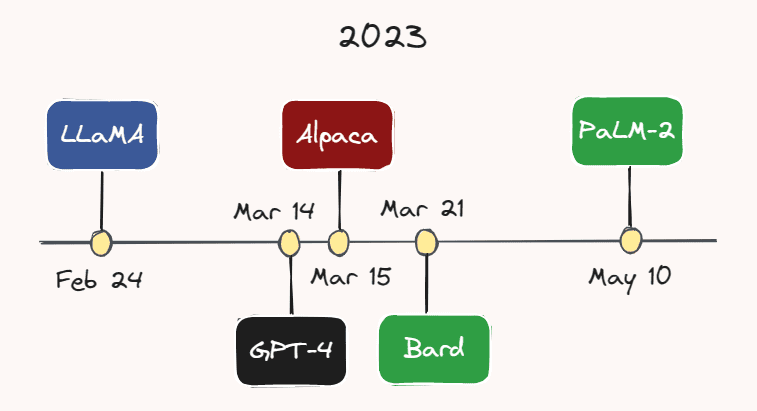 Immagine dell’autore.
Immagine dell’autore.
Ad esempio, il 24 febbraio, Meta AI ha rilasciato LLaMA – un LLM che supera GPT-3 su gran parte dei benchmark, nonostante abbia un numero considerevolmente inferiore di parametri. Meno di un mese dopo, il 14 marzo, OpenAI ha rilasciato GPT-4 – una versione più grande, più capace e multimodale di GPT-3. Sebbene il numero esatto di parametri di GPT-4 sia sconosciuto, si presume che sia nell’ordine dei trilioni.
Il 15 marzo, i ricercatori dell’Università di Stanford hanno rilasciato Alpaca, un modello di lingua leggero che è stato affinato da LLaMA su dimostrazioni di seguimento delle istruzioni. Un paio di giorni dopo, il 21 marzo, Google ha lanciato il suo rivale ChatGPT: Bard. Google ha anche appena rilasciato il suo ultimo LLM, PaLM-2, all’inizio di questo mese, il 10 maggio. Con il ritmo incessante di sviluppo in questo settore, è molto probabile che un altro modello sarà emerso al momento in cui state leggendo questo.
Vediamo anche sempre più aziende che incorporano questi modelli nei loro prodotti. Ad esempio, Duolingo ha annunciato il suo Duolingo Max alimentato da GPT-4, un nuovo livello di abbonamento con l’obiettivo di fornire lezioni di lingua personalizzate a ciascun individuo. Slack ha anche lanciato un assistente alimentato da AI chiamato Slack GPT, che può fare cose come scrivere risposte o riassumere discussioni. Inoltre, Shopify ha introdotto un assistente alimentato da ChatGPT nell’app Shop dell’azienda, che può aiutare i clienti a identificare i prodotti desiderati utilizzando una varietà di prompt.
Shopify ha annunciato il suo assistente alimentato da ChatGPT su Twitter.
È interessante notare che i chatbot AI sono considerati oggi addirittura come alternativa ai terapisti umani. Ad esempio, Replika, un’app di chatbot statunitense, offre agli utenti un “compagno AI che si prende cura, sempre qui ad ascoltare e parlare, sempre dalla tua parte”. La fondatrice, Eugenia Kuyda, dice che l’app ha una vasta gamma di clienti, che va dai bambini autistici, che si rivolgono ad essa come un modo per “scaldarsi prima delle interazioni umane”, agli adulti solitari che semplicemente hanno bisogno di un amico.
Prima di concludere, vorrei evidenziare ciò che potrebbe ben essere l’apice dell’ultimo decennio di sviluppo dell’AI: le persone stanno effettivamente utilizzando Bing! All’inizio di quest’anno, Microsoft ha introdotto il suo “copilota per il web” alimentato da GPT-4 che è stato personalizzato per la ricerca e, per la prima volta in … per sempre (?), è emerso come un serio contendente alla lunga egemonia di Google nel settore della ricerca.
Guardando indietro e guardando avanti
Mentre riflettiamo sugli ultimi dieci anni di sviluppo dell’AI, diventa evidente che abbiamo assistito a una trasformazione che ha avuto un impatto profondo su come lavoriamo, facciamo affari e interagiamo gli uni con gli altri. La maggior parte dei considerevoli progressi raggiunti di recente con i modelli generativi, in particolare i LLM, sembrano aderire alla comune convinzione che “più grande è meglio”, riferendosi allo spazio dei parametri dei modelli. Ciò è stato particolarmente notabile con la serie GPT, che è cominciata con 117 milioni di parametri (GPT-1) e, dopo ogni successivo modello aumentando di circa un ordine di grandezza, è culminata in GPT-4 con potenzialmente trilioni di parametri.
Tuttavia, sulla base di una recente intervista, il CEO di OpenAI Sam Altman ritiene che siamo arrivati alla fine dell’era “più grande è meglio”. In futuro, pensa ancora che il conteggio dei parametri aumenterà, ma il focus principale dei miglioramenti futuri dei modelli sarà sull’aumento della capacità, dell’utilità e della sicurezza del modello.
Quest’ultimo è particolarmente importante. Considerando che queste potenti strumenti di intelligenza artificiale sono ora nelle mani del pubblico e non più confinati all’ambiente controllato dei laboratori di ricerca, è ora più critico che mai che procediamo con cautela e ci assicuriamo che questi strumenti siano sicuri e allineati con i migliori interessi dell’umanità. Speriamo di vedere sviluppi e investimenti in materia di sicurezza dell’AI tanto quanto abbiamo visto in altre aree.
PS: In caso abbia omesso un concetto o una svolta fondamentali dell’AI che ritieni avrebbero dovuto essere inclusi in questo articolo, ti prego di farmelo sapere nei commenti qui sotto!
Thomas A Dorfer è uno scienziato dei dati e applicati presso Microsoft. Prima del suo attuale ruolo, ha lavorato come scienziato dei dati nell’industria biotech e come ricercatore nel campo del neurofeedback. Ha una laurea magistrale in neuroscienze integrate e, nel tempo libero, scrive anche post tecnici sul blog Nisoo sui temi di data science, machine learning e AI.
Originale. Ripubblicato con il permesso.